

使用MindStudio進行MindInsight調優
相對應的視頻教學可以在B站進行觀看:https://www.bilibili.com/vIDEo/BV1St4y1473r
一、MindSpore和MindInsight環境搭建和配置介紹
1 MindSpore簡介
昇思mindspore是一個全場景深度學習框架,旨在實現易開發、高效執行、全場景覆蓋三大目標。
其中,易開發表現為API友好、調試難度低;高效執行包括計算效率、數據預處理效率和分布式訓練效率;全場景則指框架同時支持云、邊緣以及端側場景。
昇思MindSpore總體架構如下圖所示:
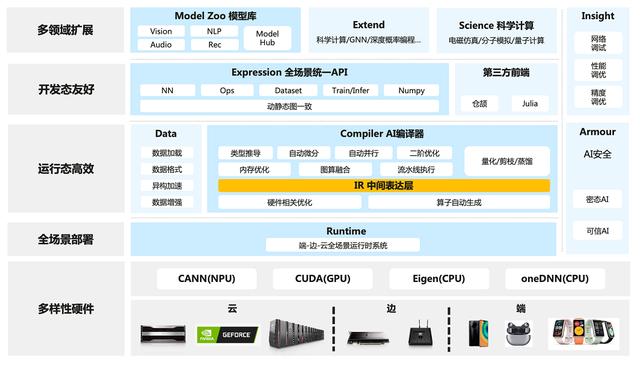

ModelZoo(模型庫):ModelZoo提供可用的深度學習算法網絡(ModelZoo地址)
Extend(擴展庫):昇思MindSpore的領域擴展庫,支持拓展新領域場景,如GNN/深度概率編程/強化學習等,期待更多開發者來一起貢獻和構建。
Science(科學計算):MindScience是基于昇思MindSpore融合架構打造的科學計算行業套件,包含了業界領先的數據集、基礎模型、預置高精度模型和前后處理工具,加速了科學行業應用開發(了解更多)。
Expression(全場景統一API):基于python的前端表達與編程接口。同時未來計劃陸續提供C/C 、華為自研編程語言前端-倉頡(目前還處于預研階段)等第三方前端的對接工作,引入更多的第三方生態。
Data(數據處理層):提供高效的數據處理、常用數據集加載等功能和編程接口,支持用戶靈活的定義處理注冊和pipeline并行優化。
Compiler(AI編譯器):圖層的核心編譯器,主要基于端云統一的MindIR實現三大功能,包括硬件無關的優化(類型推導、自動微分、表達式化簡等)、硬件相關優化(自動并行、內存優化、圖算融合、流水線執行等)、部署推理相關的優化(量化、剪枝等)。
Runtime(全場景運行時):昇思MindSpore的運行時系統,包含云側主機側運行時系統、端側以及更小IoT的輕量化運行時系統。
Insight(可視化調試調優工具):昇思MindSpore的可視化調試調優工具,能夠可視化地查看訓練過程、優化模型性能、調試精度問題、解釋推理結果(了解更多)。
Armour(安全增強庫):面向企業級運用時,安全與隱私保護相關增強功能,如對抗魯棒性、模型安全測試、差分隱私訓練、隱私泄露風險評估、數據漂移檢測等技術(了解更多)。
執行流程
有了對昇思MindSpore總體架構的了解后,我們可以看看各個模塊之間的整體配合關系,具體如圖所示:
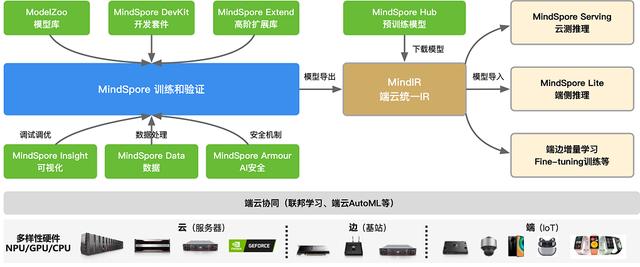
昇思MindSpore作為全場景AI框架,所支持的有端(手機與IOT設備)、邊(基站與路由設備)、云(服務器)場景的不同系列硬件,包括昇騰系列產品,英偉達NVIDIA系列產品,Arm系列的高通驍龍、華為麒麟的芯片等系列產品。
左邊藍色方框的是MindSpore主體框架,主要提供神經網絡在訓練、驗證相關的基礎API功能,另外還會默認提供自動微分、自動并行等功能。
藍色方框往下是MindSpore Data模塊,可以利用該模塊進行數據預處理,包括數據采樣、數據迭代、數據格式轉換等不同的數據操作。在訓練的過程會遇到很多調試調優的問題,因此有MindSpore Insight模塊對loss曲線、算子執行情況、權重參數變量等調試調優相關的數據進行可視化,方便用戶在訓練過程中進行調試調優。
設計理念
- 支持全場景協同
- 昇思MindSpore是源于全產業的最佳實踐,向數據科學家和算法工程師提供了統一的模型訓練、推理和導出等接口,支持端、邊、云等不同場景下的靈活部署,推動深度學習和科學計算等領域繁榮發展。
- 提供Python編程范式,簡化AI編程
- 昇思MindSpore提供了Python編程范式,用戶使用Python原生控制邏輯即可構建復雜的神經網絡模型,AI編程變得簡單。
- 提供動態圖和靜態圖統一的編碼方式
- 目前主流的深度學習框架的執行模式有兩種,分別為靜態圖模式和動態圖模式。靜態圖模式擁有較高的訓練性能,但難以調試。動態圖模式相較于靜態圖模式雖然易于調試,但難以高效執行。 昇思MindSpore提供了動態圖和靜態圖統一的編碼方式,大大增加了靜態圖和動態圖的可兼容性,用戶無需開發多套代碼,僅變更一行代碼便可切換動態圖/靜態圖模式,例如設置context.set_context(mode=context.PYNATIVE_MODE)切換成動態圖模式,設置context.set_context(mode=context.GRAPH_MODE)即可切換成靜態圖模式,用戶可擁有更輕松的開發調試及性能體驗。
- 采用函數式可微分編程架構,使用戶聚焦于模型算法的數學原生表達
- 神經網絡模型通常基于梯度下降算法進行訓練,但手動求導過程復雜,結果容易出錯。昇思MindSpore的基于源碼轉換(Source Code Transformation,SCT)的自動微分(Automatic Differentiation)機制采用函數式可微分編程架構,在接口層提供Python編程接口,包括控制流的表達。用戶可聚焦于模型算法的數學原生表達,無需手動進行求導。
- 統一單機和分布式訓練的編碼方式
- 隨著神經網絡模型和數據集的規模不斷增加,分布式并行訓練成為了神經網絡訓練的常見做法,但分布式并行訓練的策略選擇和編寫十分復雜,這嚴重制約著深度學習模型的訓練效率,阻礙深度學習的發展。MindSpore統一了單機和分布式訓練的編碼方式,開發者無需編寫復雜的分布式策略,在單機代碼中添加少量代碼即可實現分布式訓練,例如設置context.set_auto_parallel_context(parallel_mode=ParallelMode.AUTO_PARALLEL)便可自動建立代價模型,為用戶選擇一種較優的并行模式,提高神經網絡訓練效率,大大降低了AI開發門檻,使用戶能夠快速實現模型思路。
層次結構
昇思MindSpore向用戶提供了3個不同層次的API,支撐用戶進行網絡構建、整圖執行、子圖執行以及單算子執行,從低到高分別為Low-Level Python API、Medium-Level Python API以及High-Level Python API。
- High-Level Python API
- 第一層為高階API,其在中階API的基礎上又提供了訓練推理的管理、混合精度訓練、調試調優等高級接口,方便用戶控制整網的執行流程和實現神經網絡的訓練推理及調優。例如用戶使用Model接口,指定要訓練的神經網絡模型和相關的訓練設置,對神經網絡模型進行訓練,通過Profiler接口調試神經網絡性能。
- Medium-Level Python API
- 第二層為中階API,其封裝了低階API,提供網絡層、優化器、損失函數等模塊,用戶可通過中階API靈活構建神經網絡和控制執行流程,快速實現模型算法邏輯。例如用戶可調用Cell接口構建神經網絡模型和計算邏輯,通過使用Loss模塊和Optimizer接口為神經網絡模型添加損失函數和優化方式,利用Dataset模塊對數據進行處理以供模型的訓練和推導使用。
- Low-Level Python API
- 第三層為低階API,主要包括張量定義、基礎算子、自動微分等模塊,用戶可使用低階API輕松實現張量定義和求導計算。例如用戶可通過Tensor接口自定義張量,使用ops.composite模塊下的GradOperation算子計算函數在指定處的導數。
2 MindInsight簡介
MindInsight是昇思MindSpore的可視化調試調優工具。利用MindInsight,您可以可視化地查看訓練過程、優化模型性能、調試精度問題、解釋推理結果。您還可以通過MindInsight提供的命令行方便地搜索超參,遷移模型。在MindInsight的幫助下,您可以更輕松地獲得滿意的模型精度和性能。
MindInsight包括以下內容:
- 訓練過程可視 (收集Summary數據、查看訓練看板)
- 訓練溯源及對比
- 性能調優
- 精度調試
- 超參調優
- 模型遷移
3 環境安裝配置
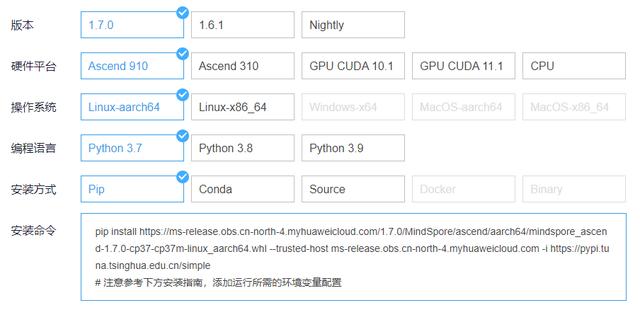
3.1 MindSpore環境安裝配置
選擇適合自己的環境條件后,獲取命令并按照指南進行安裝,或使用云平臺創建和部署模型,安裝細節參見鏈接:https://www.mindspore.cn/install
驗證是否安裝成功
方法一:
python -c "import mindspore;mindspore.run_check()"
如果輸出:
MindSpore version: 版本號
The result of multiplication calculation is correct, MindSpore has been installed successfully!
說明MindSpore安裝成功了。
方法二:
import numpy as np
from mindspore import Tensor
import mindspore.ops as ops
import mindspore.context as context
context.set_context(device_target="Ascend")
x = Tensor(np.ones([1,3,3,4]).astype(np.float32))
y = Tensor(np.ones([1,3,3,4]).astype(np.float32))
print(ops.add(x, y))
如果輸出:
[[[[2. 2. 2. 2.]
[2. 2. 2. 2.]
[2. 2. 2. 2.]]
[[2. 2. 2. 2.]
[2. 2. 2. 2.]
[2. 2. 2. 2.]]
[[2. 2. 2. 2.]
[2. 2. 2. 2.]
[2. 2. 2. 2.]]]]
說明MindSpore安裝成功了。
升級MindSpore版本
當需要升級MindSpore版本時,可執行如下命令:
pip install –upgrade mindspore-ascend=={version}
其中:
- 升級到rc版本時,需要手動指定{version}為rc版本號,例如1.6.0rc1;如果升級到正式版本,=={version}字段可以缺省。
3.2 MindInsight環境安裝配置
確認系統環境信息
- 硬件平臺支持Ascend、GPU和CPU。
- 確認安裝Python 3.7.5或3.9.0版本。如果未安裝或者已安裝其他版本的Python,可以選擇下載并安裝:Python 3.7.5版本 64位,下載地址:官網或華為云。Python 3.9.0版本 64位,下載地址:官網或華為云。
- MindInsight與MindSpore的版本需保持一致。
- 若采用源碼編譯安裝,還需確認安裝以下依賴。確認安裝node.js 10.19.0及以上版本。確認安裝wheel 0.32.0及以上版本。
- 其他依賴參見requirements.txt。
可以采用pip安裝,源碼編譯安裝和Docker安裝三種方式。
pip安裝
安裝PyPI上的版本:
pip install mindinsight=={version}
安裝自定義版本:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/{version}/MindInsight/any/mindinsight-{version}-py3-none-any.whl –trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
其中:
- 當環境中的MindSpore不是最新版本時,需要手動指定{version}為當前環境中MindSpore版本號。
注:非root用戶需要在命令中加入“–user”參數。
源碼編譯安裝
從代碼倉下載源碼
git clone https://gitee.com/mindspore/mindinsight.git -b r1.7
編譯安裝MindInsight
可選擇以下任意一種安裝方式:
1.在源碼根目錄下執行如下命令。
cd mindinsight
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
python setup.py install
2.構建whl包進行安裝
進入源碼的根目錄,先執行build目錄下的MindInsight編譯腳本,再執行命令安裝output目錄下生成的whl包。
cd mindinsight
bash build/build.sh
pip install output/mindinsight-{version}-py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
Docker安裝
MindSpore的鏡像包含MindInsight功能,請參考官網安裝指導。
驗證是否成功安裝
執行如下命令:
mindinsight start
如果出現下列提示,說明安裝成功:
Web address: http://127.0.0.1:8080
service start state: success
二、MindStudio簡介和安裝
1 MindStudio簡介
MindStudio提供在AI開發所需的一站式開發環境,支持模型開發、算子開發以及應用開發三個主流程中的開發任務。依靠模型可視化、算力測試、IDE本地仿真調試等功能,MindStudio能夠幫助您在一個工具上就能高效便捷地完成AI應用開發。MindStudio采用了插件化擴展機制,開發者可以通過開發插件來擴展已有功能。
功能簡介
- 針對安裝與部署,MindStudio提供多種部署方式,支持多種主流操作系統,為開發者提供最大便利。
- 針對網絡模型的開發,MindStudio支持TensorFlow、Pytorch、MindSpore框架的模型訓練,支持多種主流框架的模型轉換。集成了訓練可視化、腳本轉換、模型轉換、精度比對等工具,提升了網絡模型移植、分析和優化的效率。
- 針對算子開發,MindStudio提供包含UT測試、ST測試、TIK算子調試等的全套算子開發流程。支持TensorFlow、PyTorch、MindSpore等多種主流框架的TBE和AI CPU自定義算子開發。
- 針對應用開發,MindStudio集成了Profiling性能調優、編譯器、MindX SDK的應用開發、可視化pipeline業務流編排等工具,為開發者提供了圖形化的集成開發環境,通過MindStudio能夠進行工程管理、編譯、調試、性能分析等全流程開發,能夠很大程度提高開發效率。
功能框架
MindStudio功能框架如圖所示,目前含有的工具鏈包括:模型轉換工具、模型訓練工具、自定義算子開發工具、應用開發工具、工程管理工具、編譯工具、流程編排工具、精度比對工具、日志管理工具、性能分析工具、設備管理工具等多種工具。
工具功能
MindStudio工具中的主要幾個功能特性如下:
- 工程管理:為開發人員提供創建工程、打開工程、關閉工程、刪除工程、新增工程文件目錄和屬性設置等功能。
- SSH管理:為開發人員提供新增SSH連接、刪除SSH連接、修改SSH連接、加密SSH密碼和修改SSH密碼保存方式等功能。
- 應用開發:針對業務流程開發人員,MindStudio工具提供基于AscendCL(Ascend Computing Language)和集成MindX SDK的應用開發編程方式,編程后的編譯、運行、結果顯示等一站式服務讓流程開發更加智能化,可以讓開發者快速上手。
- 自定義算子開發:提供了基于TBE和AI CPU的算子編程開發的集成開發環境,讓不同平臺下的算子移植更加便捷,適配昇騰AI處理器的速度更快。
- 離線模型轉換:訓練好的第三方網絡模型可以直接通過離線模型工具導入并轉換成離線模型,并可一鍵式自動生成模型接口,方便開發者基于模型接口進行編程,同時也提供了離線模型的可視化功能。
- 日志管理:MindStudio為昇騰AI處理器提供了覆蓋全系統的日志收集與日志分析解決方案,提升運行時算法問題的定位效率。提供了統一形式的跨平臺日志可視化分析能力及運行時診斷能力,提升日志分析系統的易用性。
- 性能分析:MindStudio以圖形界面呈現方式,實現針對主機和設備上多節點、多模塊異構體系的高效、易用、可靈活擴展的系統化性能分析,以及針對昇騰AI處理器的性能和功耗的同步分析,滿足算法優化對系統性能分析的需求。
- 設備管理:MindStudio提供設備管理工具,實現對連接到主機上的設備的管理功能。
- 精度比對:可以用來比對自有模型算子的運算結果與Caffe、TensorFlow、ONNX標準算子的運算結果,以便用來確認神經網絡運算誤差發生的原因。
- 開發工具包的安裝與管理:為開發者提供基于昇騰AI處理器的相關算法開發套件包Ascend-cann-toolkit,旨在幫助開發者進行快速、高效的人工智能算法開發。開發者可以將開發套件包安裝到MindStudio上,使用MindStudio進行快速開發。Ascend-cann-toolkit包含了基于昇騰AI處理器開發依賴的頭文件和庫文件、編譯工具鏈、調優工具等。
2 MindStudio安裝
2.1 安裝Python依賴
(1)官方網站下載安裝安裝Python3.7.5到Windows本地。
(2)設置環境變量。
(3)“Win R”快捷鍵打開系統命令行,輸入“Python -V”,顯示Python版本號表示安裝成功。
(4)安裝Python3相關依賴。
pip install xlrd==1.2.0
pip install absl-py
pip install numpy
pip install requests
(5)如若返回如下信息,則表示安裝成功。
Successfully installed xlrd-1.2.0
Successfully installed absl-py-0.12.0 six-1.15.0
Successfully installed numpy-1.20.1
Successfully installed requests-2.27.1
更多安裝細節請參考:https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000022.html
2.2 安裝MinGW依賴
(1)根據電腦配置,下載適合的(下載參考地址),例如64位可以選擇x86_64-posix-seh。
(2)解壓MinGW安裝包到自定義路徑。
(3)在Windows 10操作系統的“控制面板 > 系統和安全 > 系統”中選擇“高級系統設置”,如圖所示。
(4)打開系統命令行,輸入gcc –v命令。若顯示版本號表示安裝成功。
更多安裝細節請參考:https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000022.html
2.3 安裝java依賴
(1)要求Java版本為11,參考下載地址。
(2)下載后安裝到本地,設置Java環境變量。
(3)打開系統命令,輸入java –version,如顯示Java版本信息,則表示安裝成功。
2.4 安裝Cmake
以msi格式軟件包為例,安裝步驟如下(下載參考地址),你也可以登錄CMake官網下載合適的版本
(1)單擊快捷鍵“win R”,輸入cmd,單擊快捷鍵“Ctrl Shift Enter”,進入管理員權限命令提示符。若彈出“用戶帳戶控制”提示窗口,單擊“是”。
(2)執行以下命令,安裝軟件包:
msiexec /package {path}{name}.msi
例如:
msiexec /package D:cmake-3.22.3-win64-x64.msi
(3)根據安裝向導進行安裝。
更多安裝細節請參考:https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000022.html
2.5 安裝MindStudio
(1)MindStudio官網為我們提供兩種安裝方式。大家可以選擇.zip文件,也可以選擇.exe文件。此處我選擇下載.zip文件。
(2)下載好后直接解壓到任意目錄。解壓后目錄結構如圖所示。
(3)點擊“bin”目錄,然后雙擊目錄下的“MindStudio64.exe”應用程序,運行MindStudio。

詳細安裝指導請參閱:https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000021.html
三、使用MindStudio創建訓練工程和運行腳本
1 導入模型代碼創建訓練工程
(1) 啟動MindStudio
首次啟動MindStudio會進入如下歡迎界面,大家按需選擇新建項目或打開本地項目,在這里,我點擊 Open 按鈕打開本地現存項目(https://gitee.com/mindspore/models/tree/master/official/recommend/ncf)。
(2) 選擇項目所在位置,添加 ncf 項目,點擊 OK確定。
(3) 項目結構如圖所示。
2 配置遠程環境
2.1 連接遠程服務器
(1) 點擊 Tools -> Deployment -> Configuration,配置遠程連接服務器。
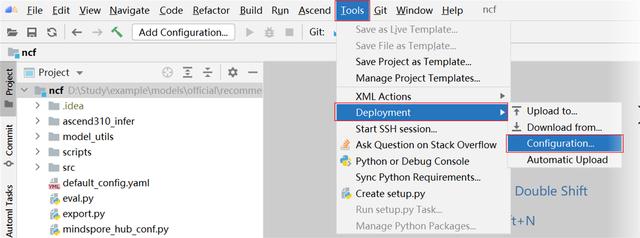
(2) 選中左側 Deployment 選項卡,點擊左上角加號,輸入自定義遠程連接名稱。
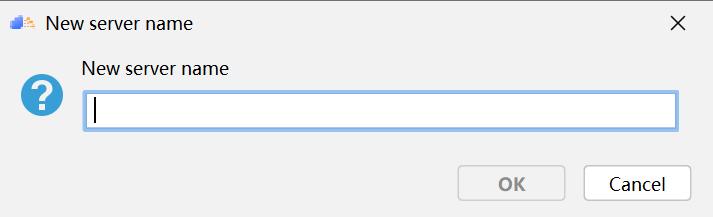
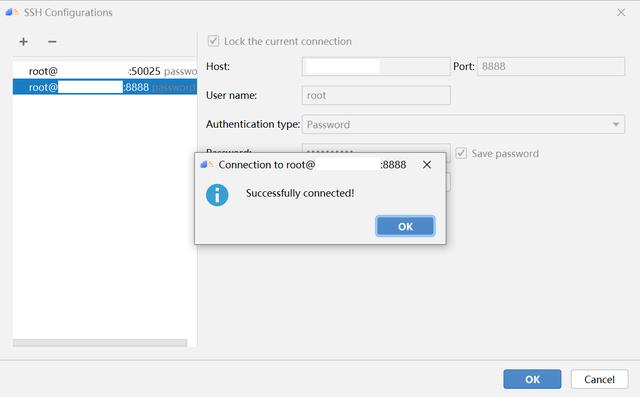
(3) 輸入服務器 IP 地址、端口號、用戶名及密碼,建議勾選 Save password 保存密碼,測試可以成功連接后,點擊OK確定。
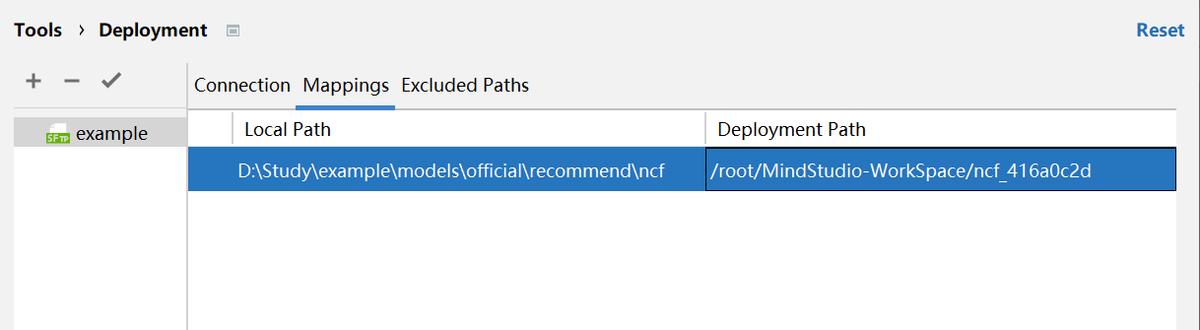
(4) 點擊 Mappings 配置本地到服務器的文件路徑映射。Local Path 填入本地項目路徑,Deployment Path 選中遠程服務器的項目路徑,這兩個文件夾名稱不必完全相同。Excluded Paths(非必需)為配置忽略路徑,表示忽略的項目文件不會上傳到遠程服務器。配置完成后,點擊 OK 確定。
2.2 設置CANN
(1) 點擊 File -> Settings,進入設置。
(2) 在左側菜單依次選中 Appearance & Behavior -> System Settings -> CANN, 進入 CANN 配置選項卡中,設置遠程服務器CANN路徑。
2.3 配置遠程SDK
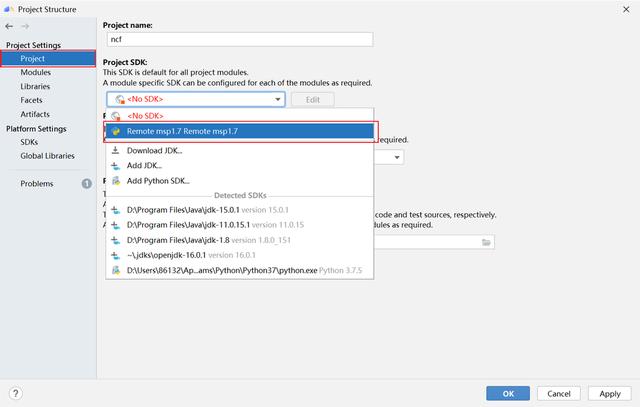
(1) 點擊 File -> Projects Structure 進入項目設置。
(2) 在左側菜單中選擇 SDKs,點擊左上角加號,選擇 Add Python SDK… 進行SDK配置。
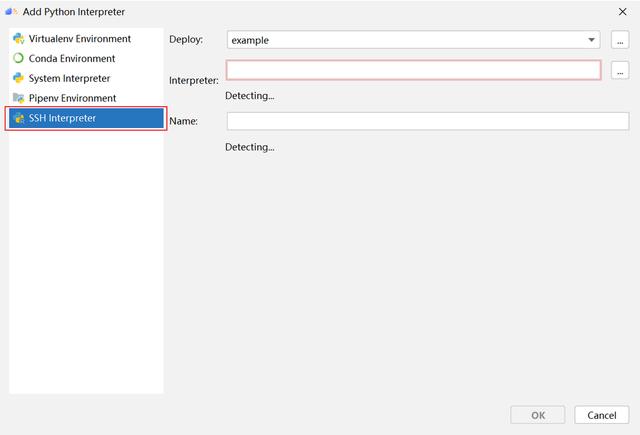
(3) 在彈出的選項卡中選擇 SSH Interpreter,在Deploy中選擇遠程連接名稱,等待 IDE 自動檢測可用的Interpreter。
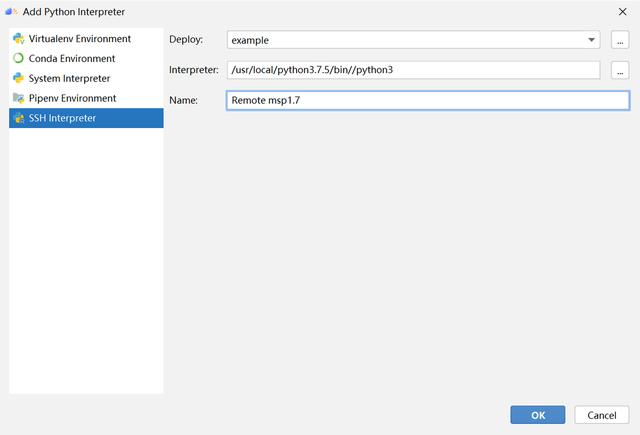
(4) 自動檢測遠程的SDK并顯示如下,可以對其進行手動修改,我將 SDK 名稱更改為 msp1.7 以便區分。
(5) 在 Project 中設置剛才配置的遠程SDK msp1.7。
3 運行訓練腳本
3.1 安裝項目依賴
(1) 點擊 Tools -> Start SSH session 打開遠程服務器終端。
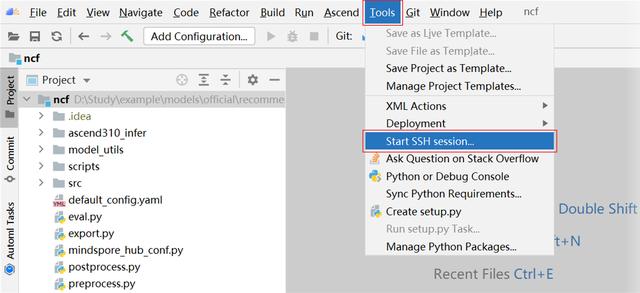
(2) 遠程服務器終端顯示在 IDE 下方控制臺處,輸入 pip list 檢查所需依賴是否已安裝。
(3) 菜單欄中點擊 Ascend -> Convert To Ascend Project,將當前項目轉換為昇騰項目。

(4) 在彈出的對話框中選擇轉換的類型和框架,此處選擇 Ascend Training 和 MindSpore 框架,點擊 OK 確定。
3.2 數據集下載和處理
(1)NCF模型介紹
NCF 是用于協同過濾推薦的通用框架,其中神經網絡架構用于對用戶交互進行建模。與傳統模型不同,NCF 不訴諸矩陣分解 (MF),其對用戶和項目的潛在特征進行內積。它用可以從數據中學習任意函數的多層感知器代替積。
詳見:https://gitee.com/mindspore/models/tree/master/official/recommend/ncf
(2)展開src目錄,右擊 movielens.py,配置運行參數。
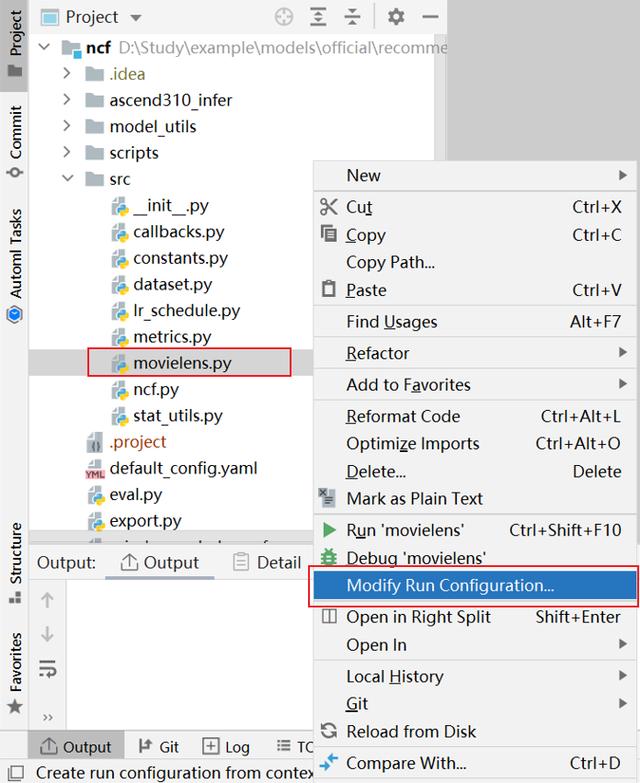
(3)配置運行參數,其中 Script path 設置為運行文件,Parameters 中設置參數,Python interpreter 選擇前文配置的遠程服務器中的 SDK,點擊 OK 確定。
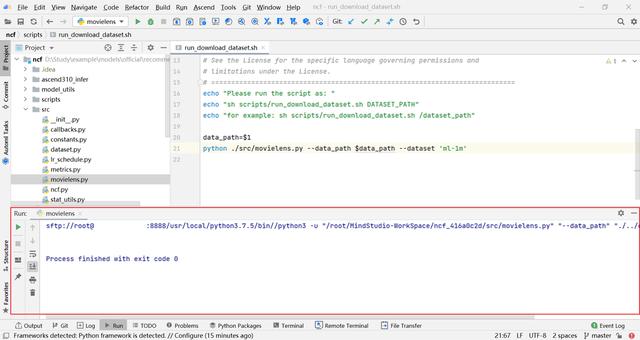
(4) 點擊工具欄中的運行按鈕,等待 ml-1m 數據集下載和預處理,大家可以在控制臺輸出查看當前程序運行的實時日志。

如果數據處理結束,會在控制臺輸出正常退出。
(5) 當運行程序后產生新的文件時,需要本地同步更新。建議大家點擊Tools -> Deployment -> Automatic Upload 開啟本地與服務器文件自動同步的功能。
(6)開啟自動同步后,更新過程如圖所示:
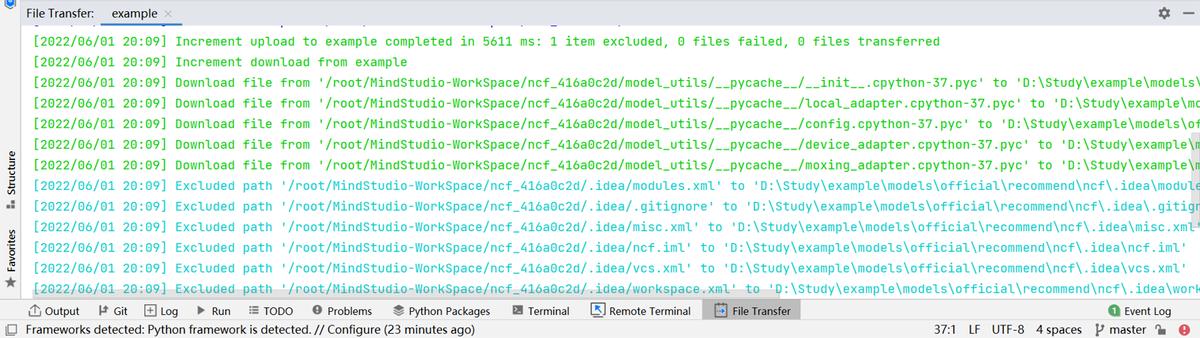
3.3 訓練項目
(1)如圖所示,點擊Edit Configuration來編輯配置
(2)設置訓練參數,此處設置了訓練20個epoch,batch_size為256,輸出保存在 ./output文件夾中,checkpoint保存在 ./nfc.ckpt 文件夾中,點擊 OK 確定。
(3)點擊運行,項目開始進行訓練。

(4)在控制臺中查看訓練過程中實時打印的日志。
四、MindInsight訓練可視化及精度調優指南
1 準備訓練腳本
(1)在train.py中,導入SummaryCollector。
from mindspore.train.callback import SummaryCollector
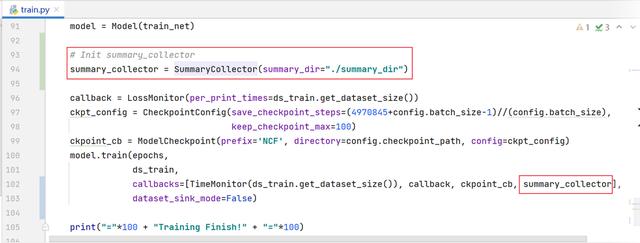
(2)在train.py代碼中,實例化 SummaryCollector,并添加到callbacks中。
# Init summary_collector
summary_collector = SummaryCollector(summary_dir="./summary_dir")
model.train(epochs,
ds_train,
callbacks=[TimeMonitor(ds_train.get_dataset_size()),
callback, ckpoint_cb, summary_collector],
dataset_sink_mode=False)
(3)增加如上代碼后,須重新訓練模型,收集的數據存放于 ./summary_dir 中。
2 MindInsight訓練可視化配置
(1)在工具欄選擇 Ascend -> MindInsight 打開 MindInsight 管理界面。
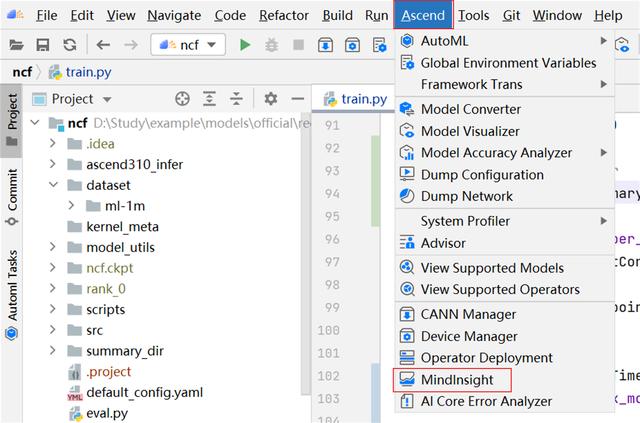
(2) MindInsight 管理界面可顯示并管理多個 MindInsight訓練可視化工程。MindInsight 管理界面相關屬性說明如下圖所示,點擊Enable按鈕,配置MindInsight組件相關參數。
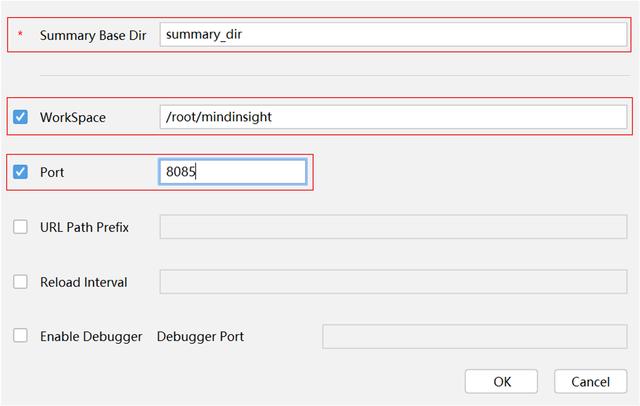
(3)在彈出的選項卡中,配置MindInsight組件相關參數,其中 Summary Base Dir 填入代碼中設置的目錄,WorkSpace 可以在 SSH 終端中輸入 mindinsight start 查看,Port為端口號。
(4)單擊 OK 完成 MindInsight 組件相關參數配置,出現如圖所示界面,說明配置成功。
(5)點擊 View 按鈕即可跳轉 MindInsight 界面。
3 查看MindInsight訓練看板及精度調優指南
代碼是精度問題的重要源頭,超參問題、模型結構問題、數據問題、算法設計和實現問題會體現在腳本中,而我們使用的MindInsight生態工具可以將腳本中的各類問題以生動的可視化數據呈現給開發者,下面我們開始探究如何使用MindInsight進行精度調優。
(1)進入訓練列表后,我們可以點擊右上角的按鈕選擇開啟/關閉自動刷新看板信息和設置刷新頻率,以及切換語言和主題。
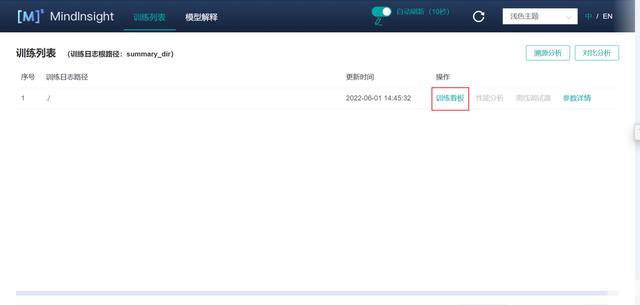
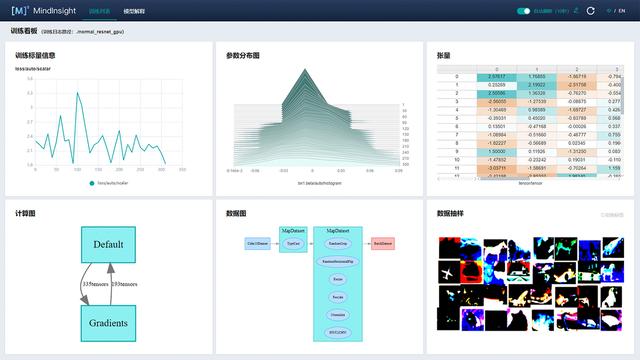
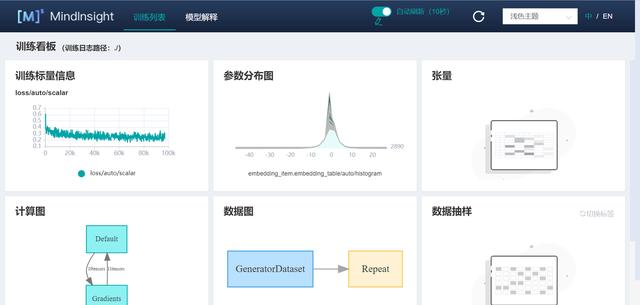
(2)點擊“訓練看板”后,可以看見訓練時的各類可視化數據。主要包括損失函數、訓練參數、訓練數據以及網絡計算圖等。
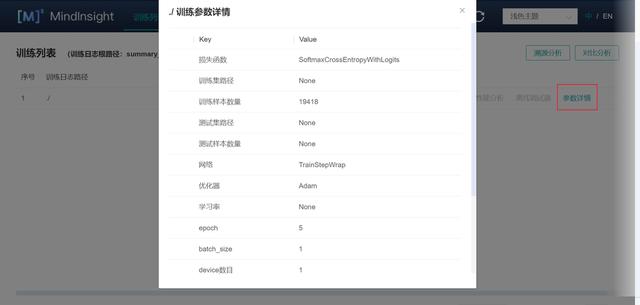
(3)點擊 “參數詳情” ,檢查超參。
MindInsight可以輔助用戶對超參做檢查,大多數情況下,SummaryCollector會自動記錄常見超參,大家可以通過MindInsight的訓練參數詳情功能和溯源分析功能查看超參。結合MindInsight模型溯源分析模塊和腳本中的代碼,可以確認超參的取值,識別明顯不合理的超參。如果有標桿腳本,建議同標桿腳本一一比對超參取值,如果有默認參數值,則默認值也應一并比對,以避免不同框架的參數默認值不同導致精度下降或者訓練錯誤。
根據我們的經驗,超參問題主要體現為幾個常見的超參取值不合理,例如:
①學習率過大導致loss震蕩難收斂,學習率過小導致訓練不充分,學習率帶來的影響可以直觀地從loss曲線觀察到;
②loss_scale參數不合理,有可能導致loss為nan或loss遲遲不收斂;
③權重初始化參數不合理等。
參數詳情可以顯示常見的超參數。如下圖所示:
(4)點擊 “參數分布圖”,可以查看網絡可訓練參數隨著迭代次數增加而產生的分布變化情況。大多數情況下,SummaryCollector會自動記錄模型參數變化情況(默認記錄5個參數),可以通過MindInsight的參數分布圖模塊查看。如果想要記錄更多參數的參數分布圖,請參考SummaryCollector的histogram_regular參數,或參考HistogramSummary算子。
(5)點擊“計算圖”,檢查模型結構。
在模型結構方面,常見的問題有:
①算子使用錯誤(使用的算子不適用于目標場景,如應該使用浮點除,錯誤地使用了整數除)。
②權重共享錯誤(共享了不應共享的權重)。
③權重凍結錯誤(凍結了不應凍結的權重)。
④節點連接錯誤(應該連接到計算圖中的block未連接)。
⑤loss函數錯誤。
⑥優化器算法錯誤(如果自行實現了優化器)等。
MindInsight可以輔助用戶對模型結構進行檢查。大多數情況下,SummaryCollector會自動記錄計算圖,點擊 “計算圖”,可以直觀地看到各個網絡節點的關系,如下圖所示:
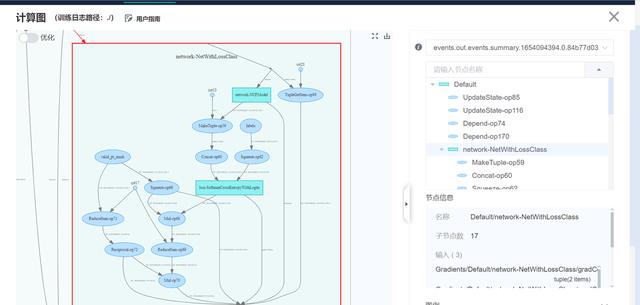
圖中左側為直觀的計算圖,右側為各節點的樹狀結構圖,點擊相應的節點可以將其展開或折疊,方便用戶查看。
(6)點擊“標量信息”,檢查loss曲線。
大多數精度問題會在網絡訓練過程中發現,并且可以直觀地體現在損失函數的圖表中,我們總結了一些可以體現在損失函數異常的常見問題:
①權重問題(例如權重不更新、權重更新過大、權重值過大/過小、權重凍結不準確、權重共享設置有誤);
②激活值問題(激活值飽和或過弱,例如Sigmoid的輸出接近1,Relu的輸出全為0);
③梯度問題(例如梯度消失、梯度爆炸);
④訓練epoch不足(loss還有繼續下降的趨勢);
⑤算子計算結果存在NAN、INF等。
如下圖,我們可以查看詳細的損失函數信息,并且面板設置有開啟/關閉Loss曲線全屏等功能,在這里可以直觀地看到損失函數的收斂趨勢以及波動幅度。
五、MindInsight訓練耗時統計及性能調優指南
1 準備訓練腳本
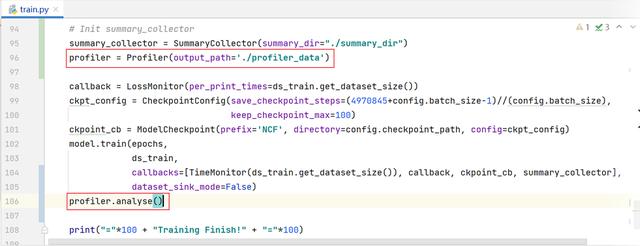
(1) 在train.py中導入Profiler。
from mindspore.profiler import Profiler
(2)收集profiler數據并分析。
profiler = Profiler(output_path='./profiler_data')
profiler.analyse()
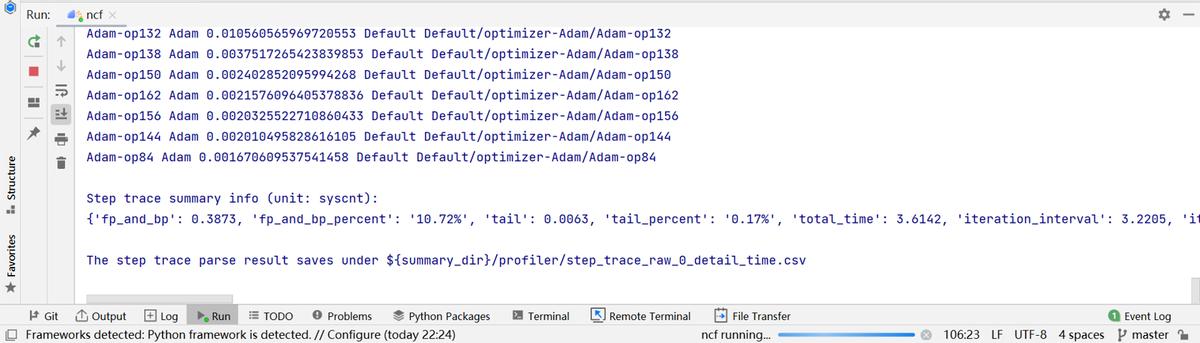
(3)再次訓練項目。此處僅僅作為模型性能調優,可以適當將訓練總分步數調小(例如兩個step,數據經過整個計算圖即可得到算子耗時)。
2 MindInsight調優配置
(1)更改MindInsight配置參數,與訓練可視化的操作相似,這里的 Summary Base Dir 填入代碼里設置的參數。
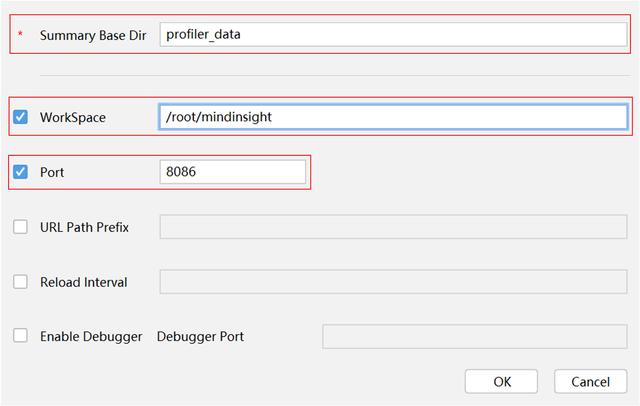
(2)單擊 OK 完成 MindInsight 組件相關參數配置,出現如圖所示界面,說明配置成功。
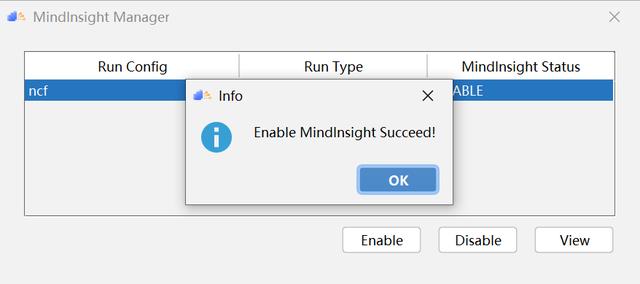
(3)點擊 View 按鈕即可跳轉 MindInsight 界面。
3 查看MindInsight性能看板及性能調優指南
(1)右上角可以選擇開啟/關閉自動刷新看板信息和刷新頻率,以及切換語言和主題。點擊 “性能分析”。
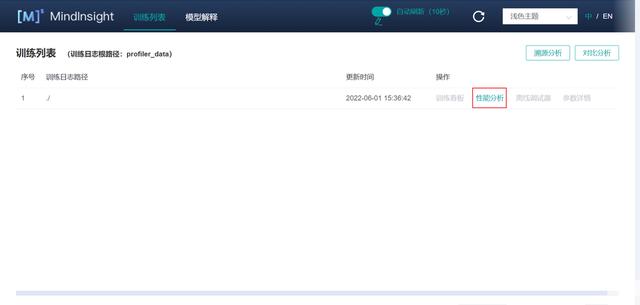
(2)進入性能分析看板后,可以看見有關訓練耗時的各類數據圖表。
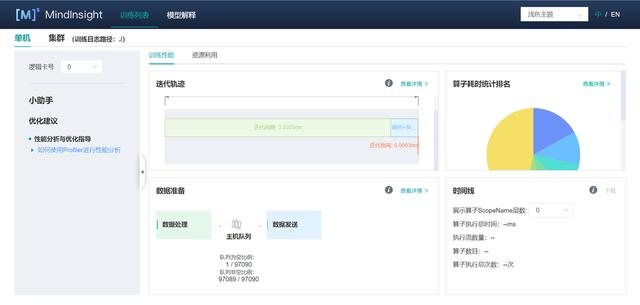
(3)點擊“算子耗時統計排名”,可以查看各個算子的執行時間進行統計展示(包括AICORE、AICPU、HOSTCPU算子)。在右上角可以選擇餅圖/柱狀圖展示各算子類別的時間占比,每個算子類別的執行時間會統計屬于該類別的算子執行時間總和。統計前20個占比時間最長的算子類別,展示其時間所占的百分比以及具體的執行時間(毫秒),我們可以選擇算子耗時排名靠前的算子進行性能優化,這樣有更大的優化空間。

(4)點擊“迭代軌跡”,查看每次迭代中各階段的耗時,確定性能瓶頸點在哪個階段,然后再針對該階段進行詳細分析。下面簡單解釋一下迭代軌跡中的三個階段:
- 迭代間隙:該階段反映的是每個迭代開始時等待訓練數據的時間。如果該階段耗占比較高,說明數據處理的速度跟不上訓練的速度。
- 前反向計算:該階段主要執行網絡中的前向及反向算子,承載了一個迭代主要的計算工作。如果該階段耗占比較高,較為合理。
- 迭代拖尾:該階段主要包含參數更新等操作,在多卡場景下還包括集合通信等操作。如果該階段耗占比較高,可能是集合通信耗時比較長。
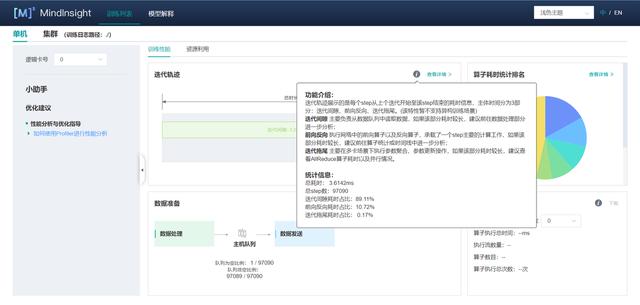
(5)進入“迭代軌跡”面板查看迭代軌跡詳情。當我們確定性能瓶頸點在哪個階段時,就可以更有針對性地進行性能優化。此處我們總結了三個階段時間異常的原因分析及解決方案:
- 針對迭代間隙過長的問題:理想情況下,某個迭代開始前向訓練時,其所需要的訓練數據已經在Host側完成了加載及增強并發送到了Device側,反映到迭代間隙耗時通常在1毫秒內,否則就會由于等待訓練數據而造成芯片算力的浪費。迭代間隙耗時長,說明該迭代開始前向計算時等待了較長的時間后訓練數據才發送到了Device側。用戶需要到“數據準備”頁面進一步確認是數據增強還是數據發送過程存在性能問題。
- 針對前反向耗時過長的問題:該階段主要包含網絡中前向及反向算子的執行時間。若該時間段耗時較長,建議按跳轉到“算子耗時統計排名”標簽頁,查看訓練過程中各算子的耗時情況,重點關注耗時排名靠前的部分算子。分享一些解決算子耗時長的小tips(歡迎補充~):在不影響精度的前提下,將float32類型修改為float16類型;存在轉換算子過多(TransData、Cast類算子)且耗時明顯時,如果是用戶手動加入的算子,可分析其必要性,如果對精度沒有影響,可去掉冗余的Cast、TransData算子;
- 針對迭代拖尾耗時過長的問題:該階段在單卡場景主要包含參數更新等操作。從實際的調優經驗來看,在單卡訓練場景下該階段耗時都很短,不會存在性能瓶頸。如果用戶遇到單卡場景下該階段耗時長,可以下載“時間線”,使用chrome://tracing工具觀察參數更新相關的算子耗時是否有異常,并到MindSpore社區 反饋。
六、FAQ
1、使用遠程conda環境無法識別conda環境里的包
原因:使用MindStudio進行遠程連接服務器資源時,默認使用/usr/local/…下的本地環境。
解決方法:可以嘗試指定運行文件為shell腳本,在shell腳本靠前位置指明source activate xxx-env來激活遠程conda環境。
2、啟動MindInsight訓練看板卡頓,單擊無響應。
解決方法:
(1)嘗試disable后重新開啟;
(2)嘗試重新存儲訓練數據;
(3)SummaryCollector實例化的參數收集頻率collect_freq設置的值過小,嘗試調大一點。
3、點擊View查看MindInsight訓練面板,顯示為空。
解決方法:Summary Base Dir 填入正確的目錄,無需加前綴“./”。
4、MindInsight訓練面板顯示異常數據(數據不符合預期)。
原因:每個summary日志文件目錄中,應該只放置一次訓練的數據。一個summary日志目錄中如果存放了多次訓練的summary數據,MindInsight在可視化數據時會將這些訓練的summary數據進行疊加展示,可能會與預期可視化效果不相符。
解決方法:將summary日志文件目錄刪除后,重新訓練生成文件。
5、訓練看板中Loss曲線過于平滑,難以分析Loss震蕩幅度。
解決方法:將model.train方法的dataset_sink_mode參數設置為False,從而以step作為collect_freq參數的單位收集數據。當dataset_sink_mode為True時,將以epoch作為collect_freq的單位,此時建議手動設置collect_freq參數。collect_freq參數默認值為10。
七、從昇騰官方中體驗更多內容
MindSpore模型開發教程與API可參考MindSpore官網:https://www.mindspore.cn/, 也可以在昇騰論壇進行討論和交流: https://bbs.huaweicloud.com/forum/forum-726-1.html
總結
本文主要介紹了如何使用MindStudio在MindSpore模型開發時使用MindInsight工具進行調優,詳細介紹了其中的MindSpore環境搭建和配置介紹、MindStudio的安裝與使用、訓練工程的導入與配置、MindInsight訓練可視化以及MindInsight性能調優等。 歡迎大家提出意見與反饋,謝謝!
