

生物信息之Seurat的安裝與使用(basecalling生物信息)
爾云間 一個專門做科研的團隊
原創 小果 生信果
歡迎點贊 收藏 關注[給你小心心]

什么是Seurat?
Seurat是R語言中被用于單細胞RNA-seq質控、分析的一個r包。從而時用戶可以鑒定來自單細胞轉錄本測定的異質性來源。
其中,Seurat包的應用主要包含了:數據導入、數據過濾、數據歸一化、特征選擇、數據縮放、數據降維、聚類、數據可視化以及差異表達基因分析的功能。
本文主要講解Seurat包的安裝以及其簡單的應用,包括數據導入、數據過濾、數據特征可視化。
Seurat的安裝
安裝命令
> install.packages('Seurat')
注意:目前Seurat最高版本是3.0版本,需要適配的R的版本在3.4及以上,如果你的R版本在3.4以上,即可直接在R中安裝。
安裝成功后引用R包可能會出現的錯誤

此時,我們需要再安裝spatstat.data這個包:
> install.packages('spatstat.data')
當安裝spatstat.data包時,可能還會出現spatstat.utils和spatstat.data版本不適配的問題,導致spatstat.data無法正確被安裝。
安裝時報錯信息:
Error: package or namespace load failed for ‘Seurat’ in loadNamespace(i, c(lib.loc, .libPaths()), versionCheck = vI[[i]]):
載入了名字空間‘spatstat.utils’ 3.0-1,但需要的是>= 3.0.2
此時,我們需要重新下載對應版本的spatstat.utils,并在下載之前刪除原來版本的spatstat.utils。
>remove.packages("spatstat.utils")
刪除原來版本的r包后,我們需要首先去下載好對應R包的壓縮包,這里需要特別注意的是,下載好的必須是.tar,而不能是.zip。這里貼下我下載的鏈接:
https://mirrors.sjtug.sjtu.edu.cn/cran/web/packages/spatstat.utils/index.html
下載好后,運行以下命令:
>install.packages("C:/下載/spatstat.utils_3.0-1.tar.gz", repos = NULL, type = "source")
(第一個空就填寫你下載好的壓縮包所在的絕對路徑即可)
如果你成功安裝了Rtools并且和R以及RStudio在同一目錄下,即可成功安裝,如果這一步仍然報錯,那么你需要檢查以下是否正確安裝了Rtools,同時也要注意R和RStudio的版本對應問題哦~
以上問題解決后,當我們在R中引用Seurat包就不會報錯了!

Seurat包的簡單使用
經過一番周折,我們成功安裝了Seurat包。接下來我們要學習怎樣使用Seurat包。

導入數據/創建Seurat對象
>library(dplyr)>library(Seurat)#導入pbmc數據>pbmc.data <- Read10X(data.dir="Rdata/filtered_gene_bc_matrices/hg19/")>pbmc <- CreateSeuratObject(counts = pbmc.data, project = "pbmc3k" , min.cells = 3,min.features = 200)>pbmc

提示信息告訴我們,生成的pbmc對象中有13714個基因,2700個細胞。
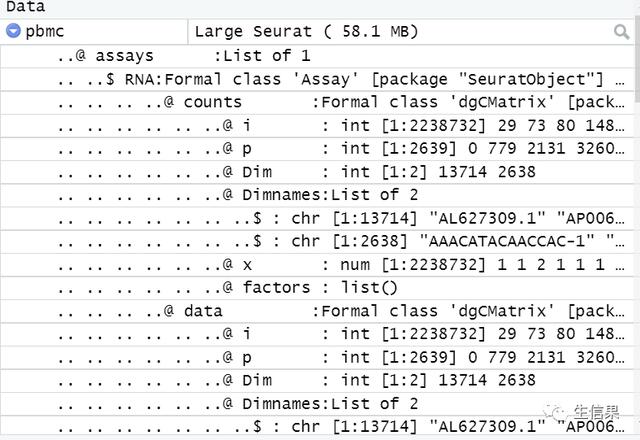
導入成功后,我們也可以在Rstudio中查看pbmc對象的整體結構如下:
數據過濾/質量控制
下面,我們以人的數據為例,以MT-開頭的所有基因集座位線粒體基因集,利用小提琴圖可視化質控指標(過濾條件:過濾線粒體基因占比大于5%的細胞、過濾UMI數大于2500或小于200的細胞)。
>pbmc[["percent.mt"]]<-PercentageFeatureSet(pbmc,pattern = "^MT-")>VlnPlot(pbmc,features = c("nFeature_RNA","nCount_RNA","percent.mt"),ncol = 3)>pbmc<-subset(pbmc,subset=nFeature_RNA>20 & nFeature_RNA <2500 & percent.mt<5)>head(pbmc@meta.data, 5)
特征-特征之間關系可視化
接下來,我們可以用FeatureScatter函數可書畫特征與特征之間的關系。
>plot3 <- FeatureScatter(pbmc,feature1 = "nCount_RNA",feature2 = "percent.mt")>CombinePlots(plots= list(plot3))
以上,就是我們對Seurat包的安裝與基本使用方法的總結,不知道有沒有幫助到你呢~

“生信果”,生信入門、R語言、生信圖解讀與繪制、軟件操作、代碼復現、生信硬核知識技能、服務器、生物信息學的教程,以及基于R的分析和可視化等原創內容,一起見證小白和大佬的成長。
