

HP AI開發平臺測評:多用戶協同開發模型和算力資源管理有力工具(hph開發)

當“人工智能步入落地之年” AI 不再是概念,而是全面進入到企業的戰略規劃之中。算力作為人工智能應用的平臺和基礎,它的發展推動了整個人工智能系統的發展和快速演進,成為人工智能的最核心要素。
隨著科技的不斷發展,獲取算力的方式和途徑越來越豐富,就目前而言,公有云和數據中心(私有云)已經成為兩大主流的算力獲取方式。不過,在實際的部署和應用中,它們對于中小型AI開發團隊來說都存在著很多問題。比如,中小型 AI 開發團隊的 AI 模型訓練往往是階段性的,而階段性訪問公有云需要按次收取算力費用,如此累積算下來將是一筆不菲的投入,相比之下,一次性購買一臺 GPU 工作站會更加劃算。而建立私有的數據中心,不僅需要批量購置 GPU 服務器,還需要搭建標準機房、高帶寬網絡部署,與此同時更需要增加專業IT維護人員的工作負荷,這對于中小型AI開發團隊來說相當奢侈。
從中小型AI開發團隊的使用場景和使用需求中不難發現,降本增效是他們衡量一款解決方案是否合適的重要因素之一。這意味著算力設備需要在保障團隊算力需求,可以共享使用的同時,還要做到簡單部署易操作,省時省力省空間。也因此,數據科學工作站的出現,可以很好地滿足這些切實需求。
數據科學工作站是 PC 形態的桌面超級計算機,相較于 PC ,它支持雙路 Intel? 至強?鉑金/金牌等系列的處理器和主板芯片海量內存、大容量 SATA 硬盤以及多塊 NVIDIA ?高端 RTX? 專業級顯卡等,可以滿足算法訓練等 AI 工作流程中所需要的強大算力需求以及圖形應用中的海量浮點運算和 3D 渲染工作等對硬件的苛刻要求。
數據科學工作站與公有云或數據中心相比,不僅性價比高,更容易部署,而且噪音低,可以讓中小型AI開發團隊直接在辦公區內進行協同開發。
惠普最近升級的 HP Z8 G4 數據科學工作站以其強大的性能表現,穩定可靠的安全性,以及全方位的系統和軟件支持,在專業領域工作環境下,為使用者提供了絕佳的高性能計算解決方案。
同時,惠普最新還推出了一款基于 Docker Kubernetes 的人工智能容器云平臺HP AI開發平臺。該平臺能夠實現異構資源的高效管理、調度和監控,提供了從模型開發、訓練到部署的完整流程和工具,廣泛適用于教育、科研、金融、醫療、能源各個行業,能極大降低人工智能進入門檻,提高人工智能創新和研發的效率。
為了讓中小型AI開發團隊更切實更全面地認識 HP Z8 G4 數據科學工作站以及 HP AI 開發平臺在團隊協作開發中的價值,智東西公開課AI教研團隊聯合兩位 Kaggle Grandmaster 模擬現實開發,對 HP AI 開發平臺的功能應用,及其在 HP Z8 G4 數據科學工作站上的使用體驗兩個方面進行了深入評測和項目實驗。
智東西公開課AI教研團隊主要承擔在 HP Z8 G4 數據科學工作站中安裝 HP AI 開發平臺,并且作為管理員進行資源管理。兩位 Kaggle Grandmaster 將基于我們分配的資源,協同完成基于數據集 CASIA-SURF 的人臉活體檢測,以及基于數據集 STS-B 的自然語言文本分類這兩項實驗。
兩位 Kaggle GrandMaster 分別是關注自然語言處理領域的算法工程師吳遠皓和從事醫療AI算法研發工作的算法工程師沈濤。吳遠皓已參加超過20場Kaggle競賽,獲得8枚金牌,并于2019年成為 Kaggle Competitions Grandmaster ,全球最高排名第36位。沈濤在機器學習競賽平臺 Kaggle 上共得到11塊金牌,獲得了 Kaggle Grandmaster 稱號,全球最高排名第8位。
在進入正文介紹 HP AI 開發平臺的功能及實驗之前,我們先來了解一下本次使用的 HP Z8 G4 數據科學工作站的核心參數,如下:

圖表0.0.1
再給大家看看3塊 NVIDIA A5000 顯卡安裝好之后的實際展示。下圖中的“三條金色模塊”即為 NVIDIA A5000 顯卡。
圖表0.0.2
下圖是 HP Z8 G4 數據科學工作站實際工作的展示:

圖表0.0.3
1、HP AI 開發平臺功能全解
本章節將為大家展示 HP AI 開發平臺的安裝過程和架構組成,并重點介紹其為開發者所提供的模型訓練、數據存儲、任務鏡像,以及向管理者所提供的用戶權限、監控中心、系統設置等特色功能。
下面進入 HP AI 開發平臺的安裝。HP AI 開發平臺的安裝包是適用于 Unix 系統和類 Unix 系統的.run 格式文件,整個安裝過程分三步,十分簡單:
第一步,在 Ubuntu 系統的終端中,輸入:
“sudo bash AI_HP -Evaluation-4.5.1-HP-63045-offline.run”即可進行安裝。
第二步,成功安裝完成后,會顯示:
“Please visit htp://192.168.88.80:5678 to continue installation.”。此時瀏覽器輸入網址后會看到平臺的環境正在初始化。
第三步,平臺環境初始化完成后,會自動跳轉到 HP AI 開發平臺的登錄界面,此時輸入賬號密碼即可完成登錄。下圖為 HP AI 開發平臺的首頁展示。
圖表 1.0.1
1、平臺架構
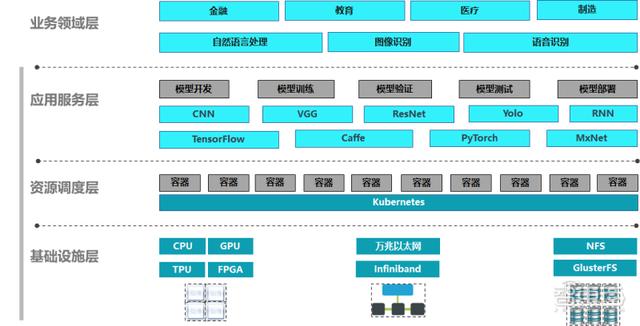
圖表 1.1.1
1.1、基礎設施層
基礎設施層以X86的服務器、專業工作站為載體,可通過 GPU、CPU 等提供高性能加速計算,支持 TCP/IP,InfiniBand 高速網絡互聯,以及 NFS 和 GlusterFS 兩種類型的存儲格式。
1.2、資源調度層
采用容器化技術管理底層資源,并利用 Kubernetes(K8s)技術進行容器編排調度。
1.3、應用服務層
應用服務層支持主流的 TensorFlow、Caffe、PyTorch 和 MxNet 等主流的機器學習框架,以及完整的機器學習所需的處理流程,實現資源操作自動化。
1.4、業務領域層
通過支持自然語言處理、圖像識別和語音識別等任務,可以滿足金融、教育、醫療、制造等行業場景的 AI 開發需求。
2、特色功能
2.1、模型訓練
2.1.1、任務列表
任務管理界面,有“任務訓練”、“交互式開發”、“可視化”、“模型部署”等四個功能頁。管理員用戶可以查看和管理所有用戶的訓練任務,包括任務訓練任務、交互式開發任務、可視化任務、模型部署任務。

圖表 1.2.1
查看任務
可以看到所有用戶的所有任務的簡要配置信息,如任務名稱、所屬用戶、任務的執行器、所屬分區、資源配額、創建時間等。點擊“任務訓練”、“交互式開發”、“可視化”、“模型部署”來展示不同類型的任務。
比如在交互式任務 “interactive14871” 中,可以分別看到任務節點、用戶名、執行器、分區名稱、資源配置、任務優先級、運行狀態、創建時間、空閑時間等。
圖表 1.2.2
點擊“詳情”可以進一步查看任務的基本信息、資源配置、應用信息和狀態等。
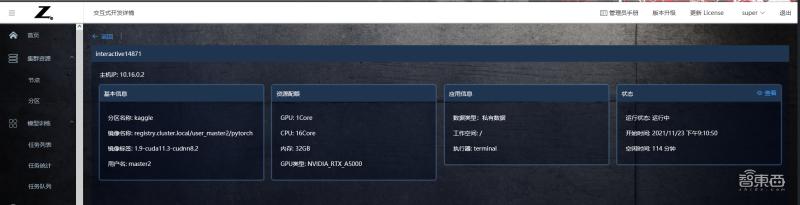
圖表 1.2.3
刪除任務
點擊“刪除”按鈕即可刪除正在運行中的任務。
需要注意的是在“任務訓練”中的任務,點擊“刪除”按鈕,只會刪除正在運行中的訓練任務,記錄無法被刪除,記錄不會占用 CPU、GPU、內存等資源,其他類型任務刪除后不保留記錄。
查詢用戶任務
在界面右側輸入框中輸入要查找的用戶名,回車進行查找。
2.1.2、任務統計
管理員可對 HP AI 開發平臺中各分區任務進行統計。查看分區中已計劃、已完成、運行中、暫停中的任務數量以及任務的資源占用信息。“任務統計”可以幫助管理員了解各分區中用戶在一段時間內使用任務訓練的使用情況。

圖表1.2.4
根據日期統計任務
管理員可選擇指定日期,統計指定日期時間到當前時間的任務數量及任務資源占用情況。
圖表 1.2.5
2.1.3、任務隊列
點擊左側菜單“任務隊列”,進入任務隊列界面,分別顯示優先級為“高”、“普通”、“低”三種優先級任務。

圖表1.2.6
2.2、數據存儲
HP AI 開發平臺支持基于 NFS 的分布式存儲方式,滿足用戶對數據的安全和性能要求。豐富的數據管理、分享功能極大方便了用戶的使用。
2.2.1、數據卷
管理員可以創建 NFS 卷,對卷進行管理操作,查看卷的使用情況。
圖表1.2.7
查看“NFS”卷列表
可以看到 NFS 數據卷列表及每個數據卷的服務器地址、共享目錄、掛載權限、狀態及描述狀態。

圖表 1.2.8
創建 NFS 卷
點擊“創建 NFS 卷”按鈕,進入NFS卷創建界面。
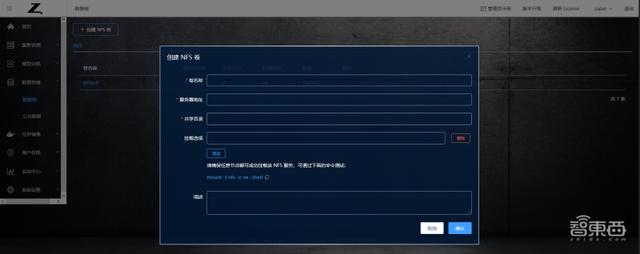
圖表 1.2.9
NFS 名詞參數解釋

圖表 1.2.10
查看卷使用情況
管理員用戶在數據卷列表頁面點擊卷名稱后,該數據卷的總使用情況和各用戶使用情況均會顯示在此頁面。
圖表 1.2.11
2.2.2、公共數據
公共數據即擁有 HP AI 開發平臺用戶都可以訪問的數據,管理員可以上傳公共數據,并對公共數據進行管理,普通用戶只有復制到用戶私有數據和下載權限。
圖表 1.2.12
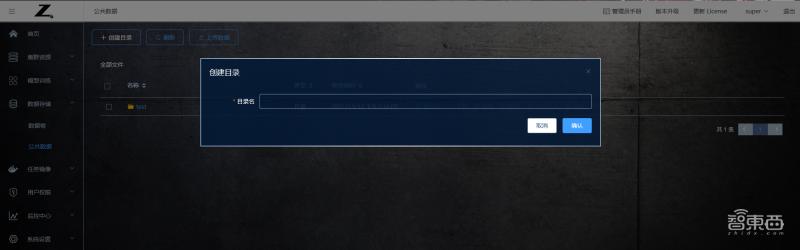
創建目錄
用戶可以在“公共數據”頁面點擊“創建目錄”來創建自己的目錄。名稱不能包含以下字符”, ‘|’, ‘*’, ‘?’, ‘,’,’/’,’ ‘, 長度在1~50個字符,創建成功會有相應提示。否則創建失敗。
圖表 1.2.13
上傳數據
將本地文件上傳到“公共數據”中。適合小文件的上傳。
圖表 1.2.14
刷新
若對文件進行了增刪修改操作,點擊“刷新”按鈕更新文件狀態及屬性。
文件列表:文件及文件夾管理
針對文件列表里面的每一個文件及文件夾,都有相應的管理功能,如重命名、下載、復制、查看文件大小、刪除等,針對文件還有在線查看功能,方便管理員進行管理操作。
圖表 1.2.15
2.3、任務鏡像
2.3.1、公共鏡像
由管理員上傳的鏡像為公共鏡像,用戶都可以看到并且可以在創建任務時使用。管理員在“下載鏡像”中下載的鏡像和上傳的鏡像均在此界面管理。此界面中管理員可對公共鏡像進行設置刪除、二次更新制作鏡像及查看鏡像詳細信息等操作。

圖表 1.2.16
上傳鏡像
管理員用戶在鏡像倉庫頁面,也可以上傳公共鏡像。
2.3.2、鏡像倉庫
管理員在鏡像倉庫頁面,可以查看各用戶的私有鏡像,或上傳公共鏡像
查看鏡像倉庫
上傳鏡像
管理員用戶在鏡像倉庫頁面,也可以上傳公共鏡像。
查看鏡像倉庫
在鏡像倉庫列表中,點擊任意用戶名,即可進入用戶的鏡像倉庫中查看用戶的私有鏡像。

圖表 1.2.19
2.3.3、下載鏡像
點擊“下載鏡像”,進入以下界面,該界面有 “ Docker Hub ”、“ HP 機器學習鏡像”和 “NVIDIA鏡像” 三個功能頁面。用戶可根據自己需要的鏡像環境去 Docker 官方鏡像倉庫Docker Hub、HP 機器學習鏡像倉庫和 NVIDIA 鏡像倉庫下載指定鏡像。
圖表 1.2.20
HP 機器學習鏡像
此功能頁預留了官方制作好的鏡像,包括 Caffe、Cuda、OpenVINO、PyTorch、TensorFlow-gpu 等11個鏡像系統。每個鏡像版本完整,并和官方機器學習框架 Release 保持一致,用戶可直接使用。
圖表 1.2.21
NVIDIA 鏡像
允許用戶查看 NGC 鏡像列表,下載使用 NGC 上 NVIDIA 提供的鏡像。

圖表 1.2.22
2.4、用戶權限
2.4.1、用戶
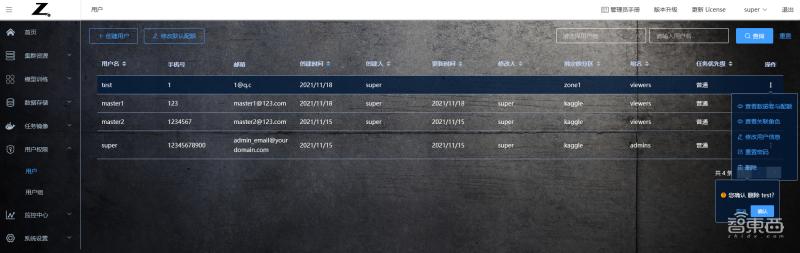
點擊左側菜單“用戶權限-用戶”,進入用戶管理界面。管理員用戶可以對用戶創建、刪除、編輯以及配置分區、存儲卷和資源配額等,對用戶的 CPU 、 GPU 、 Mem 和存儲配額進行設定,限定用戶能使用的資源數量。用戶的數據存儲空間相互隔離,每個用戶只能訪問各自空間中的數據,無法越界訪問未授權的數據。
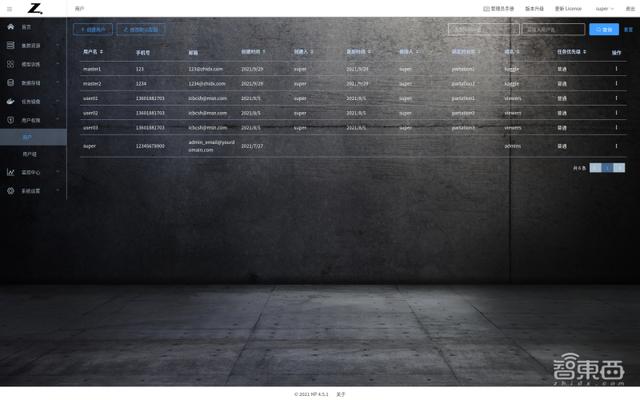
圖表 1.2.23
查看用戶
在用戶管理界面,可以查看每個用戶的手機號碼、郵箱地址、創建時間、創建人、修改時間、修改人、綁定的分區以及用戶組名。
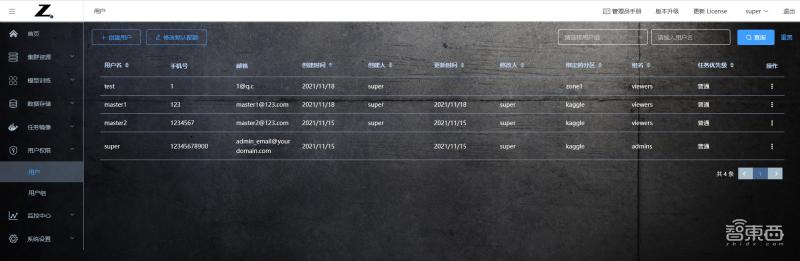
圖表1.2.24
點擊“操作”按鈕 -> 查看數據卷與配額,可以查看用戶的資源配額限定情況。
圖表 1.2.25
點擊“查看關聯角色”。
圖表 1.2.26
點擊“修改用戶信息”,可對已有用戶的手機號、郵箱、用戶組、分區和配額進行修

圖表 1.2.27
點擊“重置密碼”,可重置用戶密碼。管理員可以通過兩種方式重置用戶密碼。一種是系統自動生成密碼。如使用這種方式重置密碼,管理員只需點擊“重置密碼”按鈕即可在界面上看到新密碼;另一種重置密碼方式為管理員手動修改密碼,只需輸入兩遍新密碼,并點擊“提交”按鈕,即可修改此用戶的密碼。
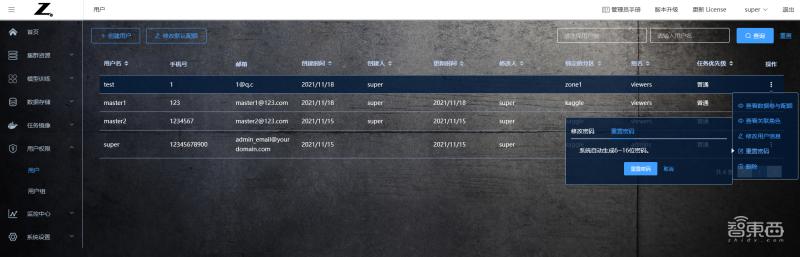
表 1.2.28
點擊“刪除”,可刪除用戶。
2.4.2、用戶組
修改默認配額
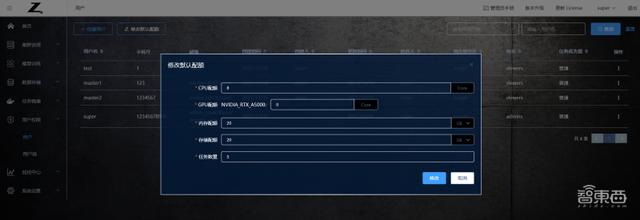
管理員用戶可以點擊用戶列表頁面上的“修改默認配額”按鈕,來修改創建用戶時默認的可使用資源配額。如 CPU 、 GPU 、內存、存儲和任務數量的默認配額。
圖表 1.2.30
創建用戶
點擊“創建用戶”按鈕,進入“創建用戶”界面后,需要填寫用戶的基本信息和配置用戶組、數據卷、分區等參數。CPU 、GPU 、內存、存儲等參數默認使用默認配額中的配置。
圖表 1.2.38
2.4.2、用戶組
管理員用戶在用戶組頁面,可以查看、創建和刪除用戶組。
圖表 1.2.32
查看用戶組
點擊“查看關聯角色”,顯示該用戶組的所有角色。

圖表 1.2.33
點擊“查看該組用戶”,顯示該用戶組的所有用戶。

圖表 1.2.34
創建用戶組
管理員在用戶組列表頁面,點擊“創建用戶組”按鈕進入創建用戶組界面,輸入用戶組名(用戶組名長度1-20個字符,不能包含字符”, ‘|’, ‘*’, ‘?’, ‘,’,’/’。),選擇不同模塊的權限,最后點擊“提交”按鈕創建新的用戶組。點擊“取消”按鈕取消創建用戶組,回到用戶組列表頁面。
圖表 1.2.35
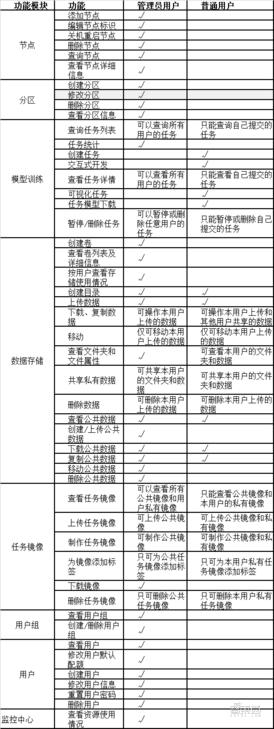
各個功能模塊不同角色的權限參照下表:
圖表 1.2.36
2.5、監控中心
2.5.1、儀表盤
儀表盤提供了多維度和多層次的監控信息,使系統使用透明、可追蹤。管理員用戶在左側菜單欄中選擇儀表盤,即可查看節點和分區的資源使用情況。
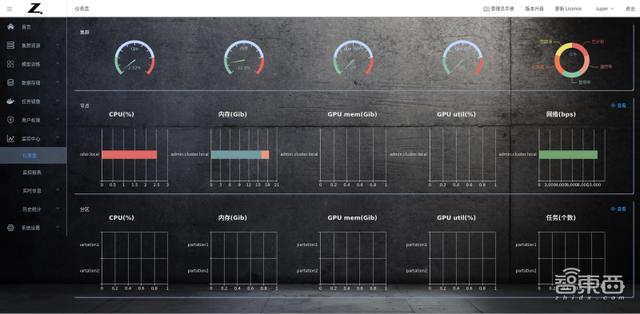
節點查看
點擊節點頁面的“查看”,可以針對某個節點監控信息進行查看。
圖表 1.2.38
分區查看
點擊分區頁面的“查看”,可以針對某個分區監控信息進行查看。
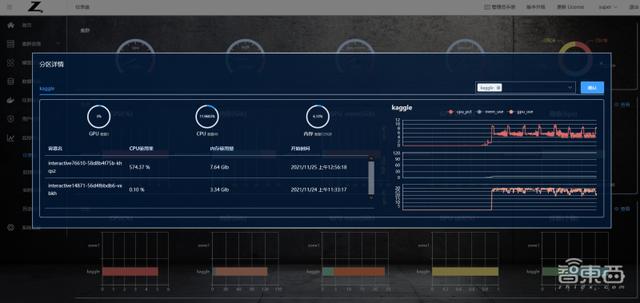
1、資源創建與分配
2.5.2、監控報表
在當前界面可以選擇 HP AI 開發平臺的節點、分區等選項來監控資源利用情況呈現可視化圖表。
圖表 1.2.40
2.5.3、實時信息
在當前界面可以選擇 HP AI 開發平臺 GPU 用途分布、GPU 使用概況、GPU 使用分布等可視化圖表。

圖表 1.2.41
管理員可以查看 GPU 的用途分布統計(任務訓練、交互式使用、可視化、空閑使用)。
管理員可以查看 GPU 的分區使用統計(總共使用,每個分區使用)。
管理員可以查看 GPU 的用戶使用統計(總共使用,每個用戶使用)。
管理員可以查看節點 GPU 使用概況(總數、空閑、已占用),以及每一塊 GPU 卡的使用率和顯存使用率。
2.5.4、歷史統計
在當前界面可以查看 HP AI 開發平臺用戶資源使用統計圖表。

圖表 1.2.42
2.6、系統設置
GPU 配置
在當前界面可以選擇 HP AI 開發平臺 GPU 類型、切片數量。

圖表 1.2.43
輸入切片數量,點擊“確認”后,即可為 GPU 切片。

圖表 1.2.44
2、實驗:人臉活體檢測和自然語言文本分類
在本章節,智東西公開課AI教研團隊將作為管理員,分配不同的賬戶資源給到兩位 Kaggle Grandmaster 進行模型開發實驗,并在平臺后端監測相應的資源使用情況和反饋。
1、資源創建與分配
1.1、創建分區 kaggle

圖表 2.1.1
圖表 2.1.2
1.2、創建用戶組 viewers

圖表 2.1.3
圖表 2.1.4
1.3、創建用戶 master1、master2
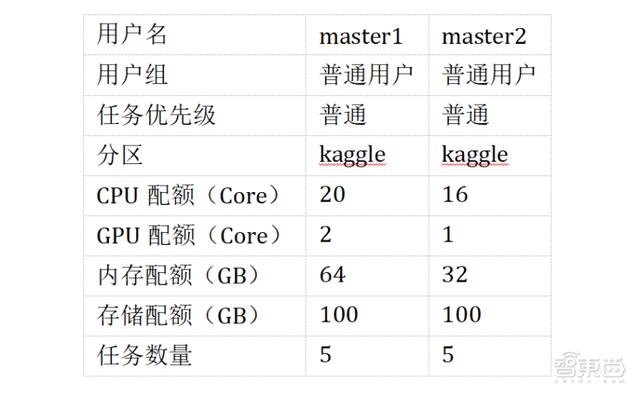
圖表 2.1.5

圖表 2.1.6
2、實驗一:基于數據集 CASIA-SURF 的人臉活體檢測
2.1、實驗說明
該部分實驗由 Kaggle Grandmaster 沈濤完成。
人臉活體檢測是人臉識別過程中的一個重要環節。它對人臉識別過程存在照片、視頻、面具、頭套、頭模等欺騙手段進行檢測,對于身份驗證的安全性尤為重要。從技術發展上,人臉活體檢測可以簡單地分為兩大類:傳統的人工特征模式識別方法和近年來興起的深度學習方法。目前,深度學習方法在識別準確性上已有較大優勢。
很多人臉識別系統利用可見光人臉圖像進行活體檢測,識別性能易受到光照條件的影響。
同時,基于可見光光譜的識別方式也很難應對常見的偽造攻擊。使用多模態數據進行活體檢測建模,能有效緩解這些問題。融合多種成像設備的圖像信息,比如可見光,近紅外和深度圖像等,既能提升模型的識別性能,也能減少光照條件對性能的干擾。
本次實驗,我們使用 HP AI 開發平臺,搭建并訓練深度學習模型,用于人臉活體檢測。數據集采用了 CASIA-SURF 集合。該數據集含有人臉可見光圖,近紅外和深度圖三種模態信息,包含了1000個個體樣本的21000段視頻。采集設備是英特爾的 RealSense 立體相機。
模型結構方面,我們會實驗多種不同架構,包括 CNN 類型的架構 FaceBagNet 模型, MLP 類的架構,(如 VisionPermutator,MLPMixer 等),還有近期非常熱門的Vision Transformer(ViT)模型。并且比對這些模型在該任務上的性能。
圖表 2.2.1
2.2、實驗流程
2.2.1、環境配置
(1)進入實驗平臺,新建交互任務 Terminal,選擇合適的鏡像,需要包含實驗所需的軟件庫( PyTorch ,OpenCV 等)。實驗平臺首頁,展示了目前的資源狀態:正在執行的任務數量,可分配的資源等。
圖表2.2.2
(2)左側欄選擇“模型開發”-“交互式開發”,并且點擊紅色框指定的新建按鈕。

圖表2.2.3
(3)進一步選擇 Terminal,設置密碼(用于后續 ssh 登陸),選擇內存大小,CPU,GPU數量。根據實驗需要設置。我們選取內存 32G ,16核 CPU,和一顆 A5000 型號的 GPU 用于本次實驗。

圖表2.2.4
(4)最下方可以選擇本地實驗使用的鏡像環境,該平臺提供了公用的基礎鏡像,我們也可以配置自己的私有鏡像環境。

圖表2.2.5
(5)創建成功后,會顯示正在運行的應用。此時可以用過命令“ssh -p 25875 root@192.168.88.80”遠程連接進行創建好的環境。
圖表2.2.6
2.2.2、實驗運行
如圖所示,模型已經開始訓練,單卡 A5000下,訓練效率很高,一個 epoch 只需要不到一分鐘的時間。同時 GPU 的占用率一直業保持在80-90%。模型的 log 文件和最終的模型文件都會存儲在對應的 Models 路徑下。在訓練開始時,終端開始打印 log ,訓練過程中 GPU 的占用率在80-90%。
2.3、實驗結果
為了有效對比多個模型的性能,我們使用該平臺訓練了多個不同結構,不同參數的模型。我們在驗證集合上測試了模型性能,使用了 ACER(Average ClassificationError Rate )指標。指標越低,說明模型性能越好。
下表展示了單一模態下,各個模型的性能比較。整體上看,使用深度圖數據的模型,會顯著優于其他兩種單一模態模型。FaceBagNet ,ConvMixer 和 MLPMixer 都有比較好的性能。
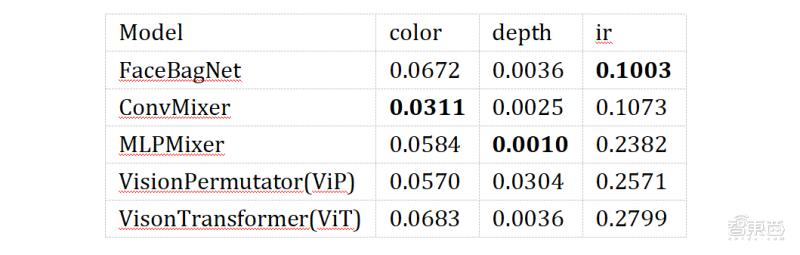
同時我們測試了三種 patch size 下,兩種多模態建模模型的性能, FaceBagNetFusion 的效果在各個參數下都顯著優于ViT模型。相比于表表2.2.7中的數據,多模態建模的結果均優于單一模態的建模結果。
圖表2.2.8
2.4、實驗感受
Q1:你在本次實驗中訓練了多個不同結構和不同參數的模型,管理員分配給你的2/3分區資源是否滿足了訓練要求?
沈濤:我的實驗主要是依賴 GPU 算力,對 CPU 和內存的需求相對較少。NVIDIA A5000 GPU 的單卡訓練效率已經足夠高,如果使用混合精度訓練等技術,效率會進一步提升。
Q2:你在本次實驗中進行了私有鏡像的上傳,是否順暢?鏡像使用中有沒有遇到兼容性或不穩定等問題?
沈濤:我以公共鏡像為基礎制作了私有鏡像。具體來說,我先申請了基于基礎鏡像的命令行的交互任務,并在任務中安裝了我所需的工作環境,并將環境保存為新的私有鏡像,后續可以直接使用。整個使用過程比較順暢,沒有出現問題。
Q3:HP AI 開發平臺提供的是 Web 端 GUI 交互界面,基于你的使用感受,你認為是否能夠降低普通開發者的使用門檻和難度?
沈濤:上述Q2中的私有鏡像保存操作就是在 GUI 交互界面完成的,這一點就比較方便,對于普通開發者,省去了 Docker 命令行操作,降低了使用門檻。同時,整個計算資源利用率的實時展示,任務的申請,都可以通過比較簡單地交互可以完成,整體上便捷一些。
Q4:對比公有云、數據中心和本地 PC ,你覺得通過工作站進行模型訓練的優勢有哪些?
沈濤:相比于公有云,數據中心,使用工作站進行模型訓練會在使用上更加便捷,數據模型都在工作站本地,減少了來回傳輸的過程,使用上也會更加穩定。相比于本地 PC ,工作站的計算性能會更強,散熱會更好,能支持長時間的高負荷工作。
Q5:對于中小型 AI 開發團隊來說,工作站 HP AI 開發平臺的算力提供和管理方式是否是一個不錯的選擇?
沈濤:對于非大規模 AI 模型(需要大規模分布式訓練)的開發,該方式已經能夠滿足正常開發需求。
3、實驗二:基于基于數據集 STS-B 的自然語言文本分類
3.1、實驗說明
該部分實驗由 Kaggle Grandmaster 吳遠皓完成。
本次實驗通過經典的自然語言文本分類數據集 STS-B 來體驗 HP AI 開發平臺。
STS-B 數據集包含8628個英語句子對,其中訓練集5749條,驗證集1500條,測試集1379條,數據集文本來源于報紙、論壇和圖片題注。該數據集也是 The General Language Understanding Evaluation (GLUE)benchmark 的一個子任務。
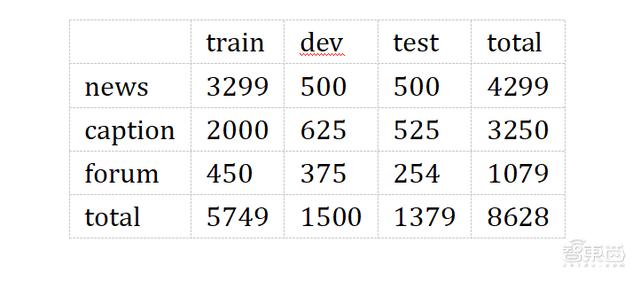
圖表 2.3.1
實驗目的是模型需要給出兩個句子的相似性度量,任務的評價指標是 Pearson 相關系數。
3.2 、實驗流程
3.2.1、環境配置
登錄 HP AI 開發平臺,在“模型訓練”-“交互式開發”中,創建 Terminal 類型的開發環境,同時可以直接在“公共鏡像”中選擇我們需要的環境。其實際使用體驗相當于一臺遠程服務器或本地 Docker。
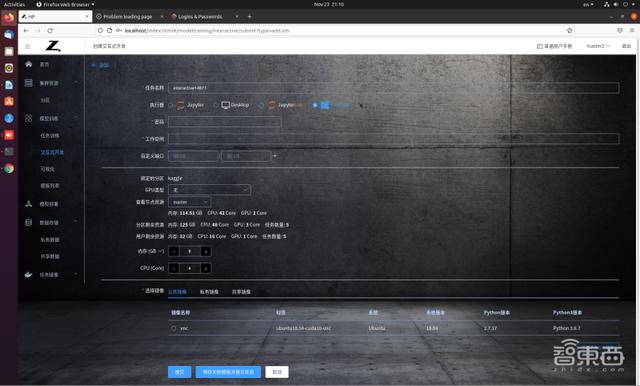
圖表 2.3.2
創建成功后,會顯示正在運行的應用。此時可以用過命令“ ssh -p 25457 root@192.168.88.80 ”遠程連接進行創建好的環境。

圖表 2.3.3
此時可以用過命令“ ssh -p 25457 root@192.168.88.80 ”遠程連接進行創建好的環境。
圖表 2.3.4
3.2.2、實驗運行

3.3 、實驗結果
本次實驗選用常用預訓練模型工具包 Transformers ,選擇的模型為谷歌開發的小型 BERT 模型 google/bert_uncased_L-2_H-128_A-2 。該模型隱層維度128,注意力頭數量為2,Transformer 層數也為2,模型大小只有不到17Mb ,是個精簡的小模型。單從實驗結果可以看出,模型在 STS-B 數據集上也取得了不錯的結果(目前榜單第一名是體積大好幾倍的 ERNIE ,其結果為0.93)。
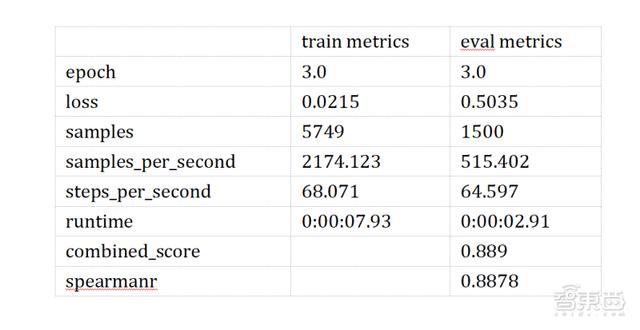
圖表 2.3.5
3.4 、實驗感受
Q1:基于本次實驗中的分區資源,你在很短的時間內就完成了基于數據集STS-B的自然語言文本分類模型的訓練,對此你怎么看?
吳遠皓:HP AI 開發平臺的各環境間互不影響,任務展示清晰透明,在多人共享資源的場景下能夠既保證開發效率,又顯著提高資源的利用效率。
Q2:HP AI開發平臺提供的是 Web 端 GUI 交互界面,請談談你的使用感受。
吳遠皓:GUI 界面非常人性化,能夠有效完成資源的組織、管理與隔離。
Q3:在完成此次實驗后,你如何評價 HP AI 開發平臺?
吳遠皓:通過體驗我們發現,HP AI 開發平臺對使用者非常友好,是計算資源管理的有力工具。
Q4:對比公有云、數據中心和本地 PC,您覺得通過工作站進行模型訓練的優勢有哪些?
吳遠皓:這幾個不太能比較。對于中小團隊來說公有云有傳輸數據的成本,數據中心的搭建和運營成本太高,而本次 PC 的性能可能達不到要求,所以為團隊配備一個共用的工作站是一種既靈活又高效的方案。
Q5:對于中小型 AI 開發團隊來說,工作站 HP AI 開發平臺的算力提供和管理方式是否是一個不錯的選擇?
吳遠皓:是的,可以發揮硬件的最大效能,提高利用率。
4、管理員后臺展示
前端用戶在通過 HP AI 開發平臺進行模型訓練過程中,管理員可以在后臺直觀的看到資源的使用反饋。比如在前面兩個實驗過程中,管理員可以在后臺看到以下內容。
4.1、任務列表
在 “任務列表” 里面,我們可以看到 master1 和 master2 創建的任務。
圖表 2.4.1
4.2、任務鏡像
在“任務鏡像”里面,管理員可以看到 master1 和 master2 所使用的鏡像系統。
圖表 2.4.2
圖表 2.4.3
4.3、監控中心
儀表盤
管理員可以看到在實驗期間,節點和分區的 CPU、GPU、內存、網絡等參數的整體使用情況:
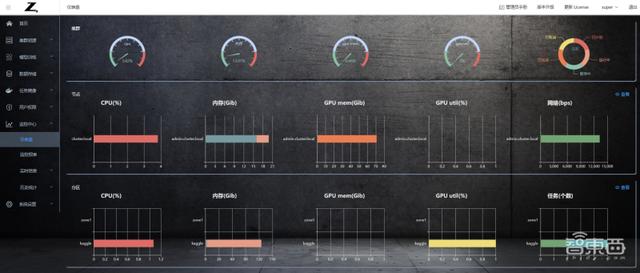
節點使用情況:
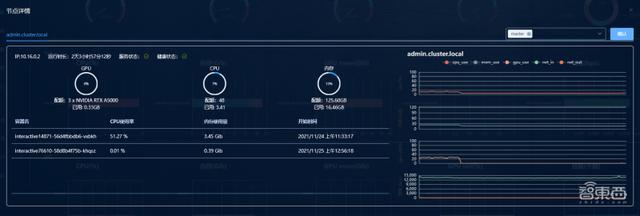
圖表 2.4.5
分區使用情況:
圖表 2.4.6
監控報表
資源使用情況:
在這里默認會選擇一周內的資源監控數據進行展示,同時也可以選擇動態展示數據變化

節點使用情況:
分區使用情況:
實時信息

圖表 2.4.7
歷史統計
圖表 2.4.8
5、多用戶使用
在 “ GPU設置” 里面,GPU 可以切片的數量選項為1、2、4、8。也就是說每塊 NVIDIA RTX A5000 的 GPU 算力可以平均分為1、2、4、8份,HP Z8 G4 數據科學工作站共有3塊 GPU,最多可將算力平均分為24份,可同時給24個開發者提供算力支持。
3、總結
通過本次專業性測試,我們可以看到,配備了3塊 NVIDIA A5000 GPU 的 HP Z8 G4 數據科學工作站在 HP AI 開發平臺的配合下,不僅便于管理員對工作站的 GPU 資源進行管理,更能滿足兩位 Kaggle Grandmaster 的算力需求,保障模型協同訓練的順暢進行。
HP AI 開發平臺是一款封裝了人工智能所需系統和底層操作的容器云平臺,在數據中心或公有云中同樣可以進行單獨的部署。不過,工作站產品特有的靜音,易部署和高性價比,讓 HP Z8 G4 數據科學工作站 HP AI 開發平臺的整體解決方案在中小企業辦公場景中的應用優勢非常顯著。
對于有同等需求的中小型 AI 開發團隊來說,搭載2-4塊 GPU 的 HP Z8 G4 數據科學工作站,配合 HP AI 開發平臺的資源管理,就可以很輕松的構建出一個性價比極高的高性能計算解決和管理方案。因此,工作站 HP AI 開發平臺解決方案可以在幫助中小企業團隊節省成本的同時,可以發揮出硬件的最大效能,提高資源利用率,成為多用戶協同開發和資源管理的有利工具。
總體來說,HP AI 開發平臺在資源管理和鏡像訂制兩方面都有著獨到的優勢。
其中,在資源管理方面有三大核心優勢:
(1)按需分配、自動釋放:在任務提交后,HP AI 開發平臺可以按照實際需求動態分配資源,限制任務無法超額使用資源,保證資源分配的公平性;與此同時,它還可以支持任務排隊機制,在任務運行完畢后自動釋放資源,讓隊列中任務自動運行;
(2)優先搶占:針對不同的優先級需求,系統可以按照從高到低順序進行任務調度,同時支持對隊列中任務的優先級調整和插隊,滿足緊急任務的使用需求;
(3)GPU 細粒度切分:系統可以根據 GPU 卡的算力,支持對 GPU 卡進行細粒度的切分;同時支持多個任務共享同一張 GPU 卡,充分提高 GPU 卡使用效率,提高任務密度和吞吐量。
另外,在鏡像訂制方面 HP AI 開發平臺有四大關鍵點:
(1)機器學習鏡像庫:可提供豐富的 TensorFlow 、PyTorch 、MxNet 和 Caffe 鏡像,且版本完整,并和官方機器學習框架 release 保持一致,用戶可以下載并導入使用;
(2)NGC 鏡像:允許用戶查看 NGC 鏡像列表,下載使用 NGC 上 NVIDIA ?提供的鏡像;
(3)自由訂制:針對用戶對鏡像的內容需求豐富且不統一,訂制化要求高等情況,系統可允許用戶通過 Docker Exec 連接并配置鏡像環境;該方式適用于所有鏡像,無需鏡像中配置 ssh 服務
(4)鏡像分享:允許管理員提升私有鏡像為公有鏡像、支持用戶私有鏡像的分享,提高鏡像獲取的效率、減少存儲空間要求。
