

AI 讀心術(shù)來了,準確率高達 82%?論文已刊登在 Nature!(ai讀心術(shù)網(wǎng)站)
整理 | 屠敏
出品 | CSDN(ID:CSDNnews)
AI 的潛力有多大?現(xiàn)如今,讀心術(shù)就要來了:人類無須張口,你的所想,AI 都知道。更為重要的是,這是 AI 首次通過非侵入式的方法學會了“讀心術(shù)”。
這項研究成果來自于美國得克薩斯州奧斯汀分校的團隊,目前已經(jīng)刊登在《Nature Neuroscience》雜志上。他們基于 GPT-1 人工智能技術(shù)開發(fā)出一種解碼器,可將大腦活動轉(zhuǎn)化為連續(xù)的文本流,它有可能為無法說話的患者提供另一種與外界溝通的新型方式。
根據(jù)實驗結(jié)果顯示,GPT 人工智能大模型感知語音的準確率可高達 82%,令人驚嘆。


“讀心術(shù)”的探索
事實上,科技圈對“讀心術(shù)”的探索并非近日才展開。
過去,馬斯克建立的神經(jīng)科技公司 Neuralink 也一直在尋找高效實現(xiàn)腦機接口的方法,其還與加州大學戴維斯分校合作,實現(xiàn)用猴子大腦控制電腦的實驗,旨在最終想要將芯片植入大腦,用“細絲”探測神經(jīng)元活動。
不過,值得注意的是,Neuralink 的這種方案屬于侵入式的。所謂侵入式,是指將腦機接口直接植入到大腦的灰質(zhì),因而所獲取的神經(jīng)信號的質(zhì)量比較高。這種方式的缺點是容易引發(fā)免疫反應(yīng)和愈傷組織(疤),進而導致信號質(zhì)量的衰退甚至消失。
與之相對應(yīng)的是非侵入式腦機接口,它是一種能夠在人腦與外部設(shè)備之間直接建立通訊的人機交互技術(shù),具有操作便捷、風險性小等優(yōu)點。
以往,行業(yè)內(nèi)可以通過功能性磁共振成像(FMRI)捕捉人類大腦活動的粗糙、彩色快照。雖然這種特殊類型的磁共振成像已經(jīng)改變了認知神經(jīng)科學,但是它始終不是一臺讀心機:神經(jīng)科學家無法通過大腦掃描來判斷某人在掃描儀中看到、聽到或思考的內(nèi)容。
此后,神經(jīng)科學家一直希望可以使用 fMRI 等非侵入性技術(shù)來破譯人類大腦內(nèi)部的聲音,而無需手術(shù)。
如今,隨著《Semantic reconstruction of continuous language from non-invasive brain recordings》(https://www.nature.com/articles/s41593-023-01304-9.epdf)論文的發(fā)布,該論文的主要作者 Jerry Tang 通過將 fMRI 檢測神經(jīng)活動的能力與人工智能語言模型的預(yù)測能力相結(jié)合,可以以驚人的準確度重現(xiàn)人們在掃描儀中聽到或想象的故事。解碼器甚至可以猜出某人在掃描儀中觀看短片背后的故事,盡管準確性較低,但也實現(xiàn)了一大進步。這也意味著,參與者不需要植入任何外界設(shè)備,AI 系統(tǒng)就能解碼大腦中的想法。

沒說過的話,AI 是怎么知道的?
自 ChatGPT、GPT-4 發(fā)布的幾個月間,我們見證了大模型根據(jù)提示詞不斷輸出內(nèi)容的過程。
要問 AI 系統(tǒng)如何了解人類大腦中的想法,在論文中,研究人員透露,首先讓參與者聽新故事,然后功能性磁共振成像(FMRI)可以呈現(xiàn)出參與者大腦的活動狀態(tài)。進而,基于最新開發(fā)的語義解碼器將這些狀態(tài),生成相應(yīng)的單詞序列,并通過將用戶大腦反應(yīng)的預(yù)測與實際記錄的大腦反應(yīng)進行比較,最終預(yù)測每個候選單詞序列與實際單詞序列的相似程度,看看準確率如何,是否能“讀心”。
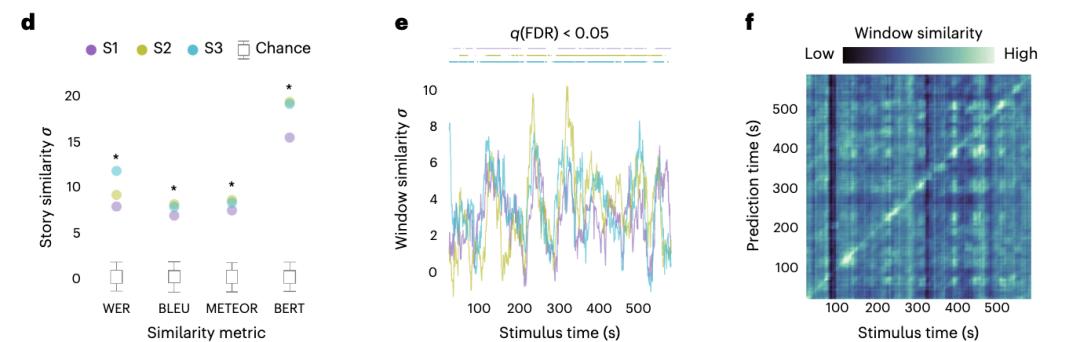
具體來看,為了收集大腦活動數(shù)據(jù),研究人員讓研究對象在 fMRI 掃描儀內(nèi)聽一些音頻故事。與此同時,通過 fMRI 掃描儀觀察他們的大腦在聽這些話時反應(yīng)情況。如圖 a 所示,3 名受試者在聽 16 小時的敘述性的故事時,AI 系統(tǒng)記錄了 MRI(磁共振成像)的反應(yīng)。

然后,MRI 數(shù)據(jù)被發(fā)送到計算機系統(tǒng)中。在這個過程中,研究人員使用了基于貝葉斯統(tǒng)計的解碼框架。大型語言模型 GPT-1 在系統(tǒng)的自然語言處理部分提供了幫助。由于這個神經(jīng)語言模型是在大量的自然英語單詞序列數(shù)據(jù)集上進行訓練的,它擅長預(yù)測最可能的單詞。
接下來,研究人員在這個數(shù)據(jù)集上訓練編碼模型。在初始訓練時,如 b 圖所示,當受試者在試聽此前沒有用于模型訓練的測試故事時,大腦會做出不同的反應(yīng)。
進而,語義解碼器可以根據(jù)參與者的大腦活動生成詞匯序列,語言模型(LM)為每個序列提出連續(xù)性,而編碼模型對每個連續(xù)性下記錄的大腦反應(yīng)的可能性進行評分。
簡單來看,語義解碼器學會了將特定的大腦活動與特定的單詞流相匹配。然后根據(jù)匹配出來的單詞流,試圖重新輸出這些故事。
不過,語義解碼器主要捕捉了參與者想法中的要點,并不是一字一句的完整思想內(nèi)容。如參與者聽到的是,“我從氣墊上站起來,把臉貼在臥室窗戶的玻璃上,希望看到有一雙眼睛盯著我,但卻發(fā)現(xiàn)只有一片黑暗。”
但是想法卻是,“我繼續(xù)走到窗前,打開窗戶,我什么也沒看見,再抬頭看,什么也沒看見。”
又比如說參與者聽到的是,“我還沒有駕照”,語義解碼器解碼之后的版本可能是,“她還沒有學會開車”。
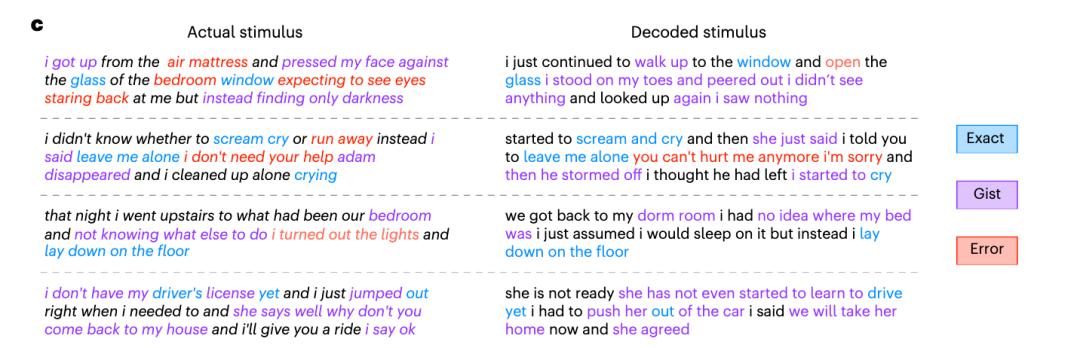
語義解碼器捕捉參與者的想法
通過這種方法,在一系列語言相似性指標下,語義解碼器對測試故事的預(yù)測與實際刺激詞的相似度明顯高于預(yù)期。準確率也高達 82%。
該論文的另一位作者 Alexander Huth 表示,他們對系統(tǒng)出色的表現(xiàn)感到驚訝。他們發(fā)現(xiàn)解碼后的單詞序列通常能夠準確地捕捉到單詞和短語。他們還發(fā)現(xiàn)他們可以從大腦的不同區(qū)域分別提取連續(xù)的語言信息。
除此之外,為了測試解碼的文本是否準確捕捉到故事的含義,研究人員還進行了一項行為實驗,通過向只閱讀解碼后單詞的受試者提問一系列問題。受試者在沒有看過視頻的情況下,能夠正確回答超過一半的問題。

語義解碼器剛起步,道阻且長
不過,當前,該語義解碼器還無法在實驗室以外的地方使用,因為它依賴于 fMRI設(shè)備。
對于未來的工作, 研究人員希望自然語言神經(jīng)網(wǎng)絡(luò)的快速進展能夠帶來更好的準確性。到目前為止,他們發(fā)現(xiàn)較大、現(xiàn)代的語言模型至少在編碼部分工作得更好。他們還希望能夠使用更大的數(shù)據(jù)集,比如每個受試者 100 或 200 小時的數(shù)據(jù)。
雖然這種非侵入性的方式,可能會對醫(yī)學維度的研究以及患者有極大的好處,使其可以與他人進行可理解的交流,但是也存在隱私、倫理審查、不平等和歧視、濫用和侵犯人權(quán)等諸多問題,所以想要現(xiàn)實中應(yīng)用也大有難度。
與此同時,研究人員表明,語義解碼器僅在接受過訓練的人身上以及與其合作下才能正常工作,因為針對一個人訓練的模型不適用于另一個人,當前還無法做到通用。
“雖然這項技術(shù)還處于起步階段,但重要的是要規(guī)范它能做什么,不能做什么,”該論文的主要作者 Jerry Tang 警告說。“如果它最終可以在未經(jīng)個人許可的情況下使用,就必須有(嚴格的)監(jiān)管程序,因為如果濫用預(yù)測框架可能會產(chǎn)生負面后果。”
該小組已在 GitHub 上提供了其自定義解碼代碼: github.com/HuthLab/semantic-decoding。據(jù)悉該團隊也在得克薩斯大學系統(tǒng)的支持下提交了與這項研究直接相關(guān)的專利申請。
https://www.nature.com/articles/s41593-023-01304-9
參考:
https://spectrum.ieee.org/mind-reading-ai
https://www.auntminnie.com/index.aspx?sec=ser&sub=def&pag=dis&ItemID=140000
