

還在猶豫要不要用 TDengine 3.0?四大企業應用案例合集給你參考
TDengine 3.0 自 2022 年 8 月于 TDengine 開發者大會正式亮相后,至今已經歷多次更新迭代,不久前發布的《3.2.1.0 發布!時間轉換函數 BI 集成 視圖正式上線!》(https://www.taosdata.com/tdengine-engineering/22452.html)為大家介紹了最新版本 3.2.1.0 的優化詳情。可以說,經過產品研發人員和社區用戶的不斷努力,3.0 的穩定性和易用性也在不斷提升。在 3.0 版本中,我們對產品底層進行了全面的變化和調整,除了架構的科學性和高效性外,還將用戶體驗作為重點優化方向之一。
為了讓大家更深入地了解到 TDengine 3.0 在實際企業環境中的應用和效果,本篇文章匯總了四個真實的企業部署實踐案例,給到有需要的用戶參考。
中國地震臺網中心 x TDengine 3.0
“在地震監控領域的可視化中,最重要的就是展示信息的完整性、實時性、可交互性,靈活性。TDengine 高效的查詢能力以及簡單易用的 SQL 語句可以很方便的完成上述工作。通過網頁展示工具調用 TDengine 的 SQL,我們完成了展示地震事件的主看板:看板中的地圖可以展示臺站的每秒峰值記錄,點擊近期地震事件便可以進行一段時間(例如該地震發生時刻前 1min 和后 2min)內的地震數據回放。”
業務背景
近年來,隨著地震臺站密集建設,臺站儀器采集匯入中國地震臺網中心的地震波形數據也增長了一個數量級。地震波形數據主要是指由國家地震臺站、各省區域地震臺網等地震觀測網絡系統中地震計采集并傳回中心的數據,具有典型的時序數據特征,是開展地震監測預警、數據分析與挖掘、地震異常研判等應用的基礎材料。為滿足地震預警數據存儲、檢索和處理的建設與集成需求,以及響應國家國產軟件自主可控的號召,中國地震臺網中心決定選用國產數據庫 TDengine 來存儲和處理地震波形數據。
架構圖
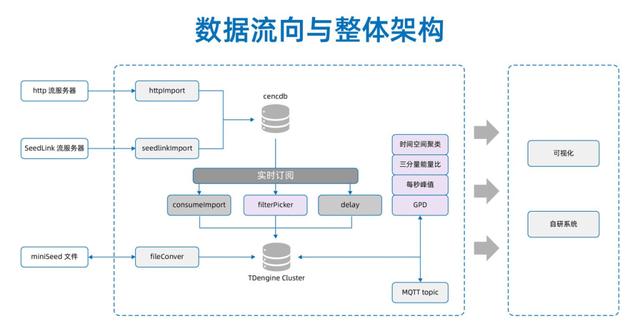

改造效果
該項目目前使用的是 3.0.6.0 版本的 5 節點集群,單臺服務器配置為:48CPU(s), 192GB 內存 ,500GB SSD 1.2TB *6HDD 硬盤。項目運行至今,TDengine 接入的原始數據包每天約 900GB,每秒大概接入超過 5 萬個地震數據包,每天總數據量約 5000 億條。對于常規的 INT 類型數據,TDengine 壓縮比可達到 5%-10% 之間,對于 VARCHAR 類型的數據,壓縮比可達到 15-20%,極大程度地節約存儲成本。在集群日常負載上,單臺數據庫服務端 CPU 使用率 40%~50%,內存占用 14%~20%,運行平穩。
點此查看案例詳情
https://www.taosdata.com/tdengine-user-cases/19268.html
中移物聯 x TDengine 3.0
“我們當前使用的是 3.0.2.5 版本,但是由于業務本身不允許停機,所以沒辦法做離線升級,后續會由 TDengine 企業版團隊協助我們在線升級至最新版本。TDengine 3.0 的安裝部署上保留了和 2.0 一樣的簡單易用模式,升級操作只需要備份數據文件目錄,覆蓋安裝即可,而且寫入速度極高,接近硬盤的連續寫入性能。”
業務背景
在中移物聯網的智慧出行場景中,需要存儲車聯網設備的軌跡點,還要支持對車輛軌跡進行查詢。為了更好地進行數據處理,他們在 2021 年上線了 TDengine 2.4.0.18 版本的 5 節點 3 副本集群,一直穩定運行。3.0 發布后又經過幾度優化,中移物聯網關注到了這一版本的眾多特性,包括 Raft 協議的引入使 TDengine 擁有了更標準的一致性算法、存儲引擎的重構優化了 2.x 版本的設計、查詢靈活度大幅提升、支持更強大的流式計算等等。在經過進一步調研后,其決定進行從 2.x 到 3.x 的大版本升級。
架構圖
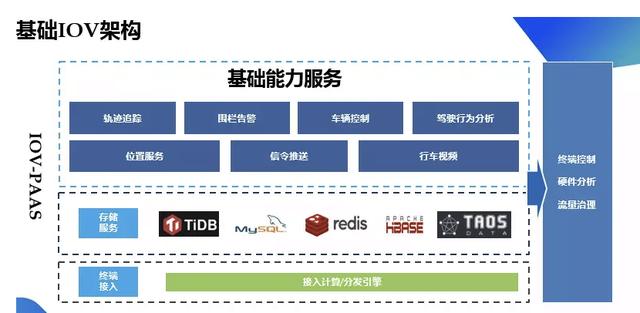
改造效果
目前該項目共有 102 萬張子表,已經累積的總數據量已經達到了 2000 億行,3 副本,磁盤占用 3.1TB。在遷移到 TDengine 3.0 之后,各方面的表現依然非常不錯:業務的寫入峰值達到了 1.2-1.3w 行/s ,數據遷移的過程中可以達到 20w 行/s,這些情況下 TDengine 都可以輕松處理;存儲大約只有 MySQL 的 1/7;讀取數據性能也很突出,其最常用的單設備單日查詢,可以在 0.1s 內返回結果。
點此查看案例詳情
https://www.taosdata.com/tdengine-user-cases/18077.html
搜狐基金 x TDengine 3.0
“由于‘超級表’的存在,數據建模變得非常清晰,幾乎所有查詢都可以以‘超級表’為核心用簡單的 SQL 完成。此外,基于‘自動建表’這個特色功能,我們可以無需校驗就能夠直接建表,這讓我們得以非常輕松地完成各只基金數據的拆分建表以及寫入工作。”
業務背景
對于搜狐基金來說,其所購買的數據源的基金數據都是混在一起的,包含來自國內的 2 萬只基金,跨越幾十年(從九幾年至今)的數千萬行較寬的數據。此前他們通過 MySQL 來存儲這些數據,首先要把每個基金的數據分表,有一定程度的工作量,只能先全量保存這些數據在一張表中,但這種大表會導致查詢的性能非常低下,為了應對這一問題,只能通過離線查詢生成每天的基金數據圖片返回給用戶,無法對外提供自定義查詢服務。在此背景下,搜狐基金決定基于 TDengine 3.0 嘗試一下全新的方案。
建模展示
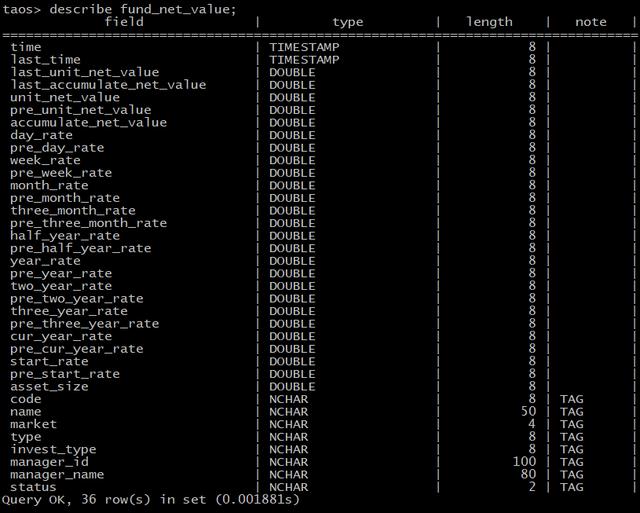
改造效果
我們使用三臺 4C 16GB 的服務器組建了 TDengine 的集群。值得一提的是,基金數據是一日一條,屬于低頻次數據。對于這種數據,默認的配置是不夠的。一開始我們的查詢性能并不快,基本都是在秒級別甚至還有更高。通過文檔和博客以及官方團隊的支持,我們放大了 duration 和 stt_trigger 參數,這樣確保了不會產生過多的文件碎片影響讀寫性能,后續的查詢全部被優化至毫秒級別。
點此查看案例詳情
https://www.taosdata.com/tdengine-user-cases/22138.html
智光電氣 x TDengine 3.0
“當前 TDengine 3.0 已成功應用于我司多個工業項目中,涵蓋數萬臺各類工業設備的數據存儲與查詢。作為數據中臺,TDengine 為上層應用提供了高效的歷史數據查詢,精確到秒級和分鐘級粒度,幫助我們大幅提升了應用效率,同時減少了硬件和人力資源的消耗。”
業務背景
在使用 TDengine 之前,子公司智光研究院在工業項目中使用基于 Apache Hadoop 的 CDH 集群來做時序業務數據的處理。但是由于數據量級太大,處理占用了大量資源,導致集群的不穩定性增加,有頻繁發生崩潰的風險。經過充分測試后,該團隊最終決定把由 HBase 處理的、數據量最大的時序數據業務抽離出來,引入 TDengine 來降低 Hadoop 集群的壓力,成為獨立出來的數據中臺。
改造后部分查詢展示
改造效果
寫入存儲方面,同樣是列式存儲,以半年的數據作為比較,三副本的 HBase 的總數據量占用是 10TB,TDengine 三副本的磁盤占用只有 2TB,存儲成本僅為 HBase 的 20 %。(由于和其他應用共用,內存、CPU 方面不好估算,但成本均大幅降低)
在查詢上,智光研究員的業務主要就是針對 rundata_t1m(分鐘級數據)、rundata(原始數據)這兩張千億級別的大型超級表的篩選、過濾、降采樣。應用的查詢性能和 SQL 篩選的時間范圍相關較大,整體上的耗時大概在毫秒級至 2 秒內。
點此查看案例詳情
https://www.taosdata.com/tdengine-user-cases/22521.html
結語
通過上述案例我們能看到,在經過不斷打磨優化后,如今的 TDengine 3.0 已經在性能、功能、穩定性各個方面均有大幅提升,從一款時序數據庫(Time Series Database,TSDB)蛻變成為高性能、云原生、分布式的物聯網、工業大數據平臺。為此,我們也強烈建議老用戶盡快向 TDengine 3.0 版本進行遷移,以便體驗到 TDengine 更加強大的產品力。
為了幫助大家最短時間內在本地完成自助式版本遷移,除了官方文檔以外,我們還準備了大量技術文章,全部匯總在《萬字解讀|怎樣激活 TDengine 最高性價比?》(https://www.taosdata.com/tdengine-engineering/21550.html)中,以供有需要的用戶參考。
