

你想了解什么是數學建模么?看這篇文章就夠了(什么叫數學建模-)
1.「數學建模」的過程主要有哪些?
數學建模的定義
這里引用下我老師寫的新書中對數學模型和數學建模的定義,我覺得算是一個比較不錯的版本,這里分享給大家:
數學模型是利用系統化的符號和數學表達式對間題的一種抽象描述。數學建模可看作是把問題定義轉換為數學模型的過程。 和問題定義相對應,數學模型包括幾個主要組成部分:決策變量、環境變量、目標函數和約束條件。決策變量表示決策者可以控制的因素,即可控輸入,是需要通過模型求解來確定的模型中的未知變量。環境變量表示決策者不可控的外界因素,即非可控輸入,需要在收集數據階段確定其具體數值,并在模型中以常量表示。目標函數是指描述問題目標的數學方程,而約束條件則是指描述問題中制約和限制因素的數學表達式(等式或不等式)。(這個主要是規劃的一種定義) 數學建模是一項富有創造性的工作。對任何問題,“沒有唯一正確的模型”。數學模型是對現實問題的一種抽象描述,必然會忽略一些因素。而這些被忽略的看似無關或不重要的因素,可能會引起重大的變化,例如人們熟知的“蝴蝶效應”。著名的統計學家喬治·博克斯曾說過:“All models are wrong.Some are useful.”(所有的模型都是錯誤的,但有一些是有用的。)對同一問題,可以從不同角度對其構建出多個不同的模型。 對于復雜問題的建模,很難一步到位,通常需要采取一種逐步演化的方式來進行。從簡單的模型開始(忽略一些難以處理的因素),然后通過逐步添加更多相關因素,讓模型演化,使其與實際問題更加接近。基于模型分析得出的結論或建議的價值,與模型對實際情況的描述符合程度有很大的關系。通常,模型越接近實際,分析得出的結果的價值也越大。
除此之外,美國最為權威的數學建模參考書Mathematical Modeling 在前言部分對數學建模也有著一個比較通俗易懂的解釋:
Mathematical modeling is the link between mathematics and the rest of the world. You ask a question. You think a bit, and then you refine the question, phrasing it in precise mathematical terms. Once the question becomes a mathematics question, you use mathematics to find an answer. Then finally (and this is the part that too many people forget), you have to reverse the process, translating the mathematical solution back into a comprehensible, no-nonsense answer to the original question. Some people are fluent in English, and some people are fluent in calculus. We have plenty of each. We need more people who are fluent in both languages and are willing and able to translate. These are the people who will be influential in solving the problems of the future.
翻譯的拙作見下:數學建模是數學與世界其他地方(其他領域)之間建立的聯系的方法。您提出一個問題,然后稍作思考,然后細化問題,最后以精確的數學術語表述。一旦問題變成數學問題,您就要使用數學來找到答案。最后,最后(這是很多人忘記的部分),您必須逆轉這一過程,將數學解轉換回對原始問題的可理解的,有意義的答案。
我們知道,有些人說英語流利,有些人做微積分運算熟練,擅長不同領域的人多種多樣。我們需要精通不同領域的人并且愿意將不同領域進行轉化,這些人將對解決未來的問題產生影響。
這兩本書實際上都清晰地說明了數學建模的特點,一個從方法上,一個從思想上。這里我稍微總結一下:
從思想上:
從思想上來說,數學建模是構建數學與其他學科之間的橋梁。我們所謂的交叉學科,很大概率就是以數學、統計學、物理學作為理論基礎,計算機作為計算或可視化利器,對某些學科進行定量分析。比如現在流行的生物信息學、整合生命科學、商業分析,或者Computational XX的相關學科,基本上都和數學建模相關。
從技術上:
從技術的角度上來說,數學建模從來都不是強迫癥的樂園。因為,我們通過上文已經得出,數學模型本身是不完美的,因此我們要容忍一定程度上模型對原型的“失真”。并且由于選擇的因素的側重點不同,很有可能兩個團隊使用了不同數學領域的方法對問題進行分析并建立模型。但是,正是這些丑陋并且存在誤差的模型,解決了我們生活中很多方方面面的問題。數學模型的建立、求解和應用是人類的理論向著社會應用的一大躍進。
數學建模的主要過程
下面主要來談談數學建模的主要過程,或者我可以說是數學建模的整個生命周期是怎么樣的。這里我同樣使用中外兩個不同版本的教科書對這個問題的看法,首先第一本是大家參加數學建模競賽中可能已經使用過的教材:A First Course in Mathematical Modeling,這本教材中出現的數學建模五步法 ,應該是大家耳熟能詳的,這里給大家分享一下:


數學建模五步法
下面是我老師教材中關于數學建模的一般流程 。這個流程與數學建模五步法相比,更加貼近實際項目中的流程,這里我使用AxGlyph繪制下改流程圖:
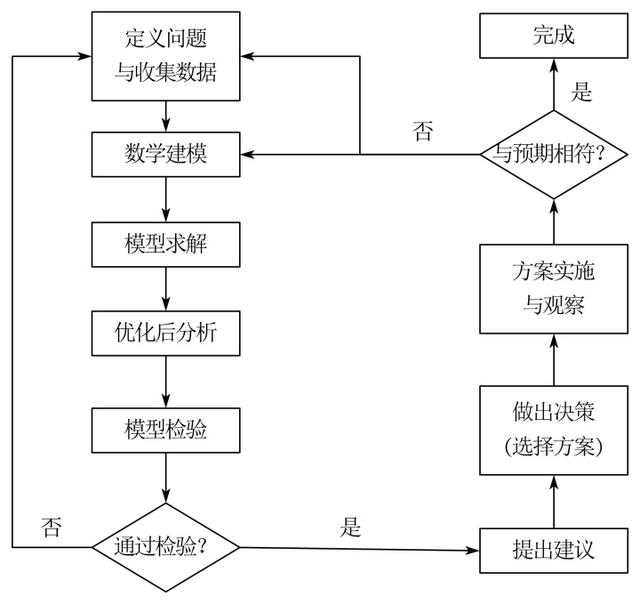
基于模型解決問題的一般流程
這個流程圖便是基于模型解決問題的一般流程,數學建模五步法與其相比更加精簡,更適合在數學建模競賽中應用,而該流程在實際生活中更具指導意義。還有一種是我們數學建模競賽中常常走的寫作套路,這里也和大家分享一下:
摘要1.問題重述(背景介紹、文獻綜述、問題重述等)2.問題分析(主要對問題進行一定的分析,可以做一個分析流圖)3.問題假設(其實也就是對問題的邊界進行劃定,我們需要讓問題更具體一些)4.符號說明(對于文章中主要出現的符號進行一定的解釋,方便評委老師理解)5.模型建立與求解(這一步最為核心,即數學建模和模型的求解部分)6.靈敏度分析(即分析模型的輸出,對參數或環境變化的敏感程度的分析)7.模型的推廣及優缺點(主要對模型的進一步研究分析和優缺點解釋)參考文獻附錄
我們可以對基于模型解決問題的一般流程中的步驟進行一定的分析:
首先是定義問題和收集數據環節。我認為這是上述流程中最為困難也最容易讓人感到很虛無縹緲的一個部分。首先,由于我們每個人說話的方式和對問題的理解程度不同,可能同一件事務,從不同的人口中或者行為中或者情感中表現出來是不太一樣的。其實有一個游戲就是利用了這種特點,這種游戲叫做心有靈犀游戲 ,意思就是說,一個人看到一個詞匯,通過扮演這個詞匯,讓另外一個人理解并且將這個詞說出來。一般而言,不經過一定程度的訓練,是很難讓兩者協調地進行這個游戲的。或者我們換一個理解,更簡單地說,我們知道存在失真這個名詞,我們不同的人對一個事務的理解,都會存在不同程度的失真,然后再通過語言或者其他行為傳遞處于會形成二次失真。下面我引用一段話 :
如果負責解決問題的人和負責提出問題的人對問題的理解不同,其結果可想而知。從“錯誤”的問題出發,很難得出“正確”的答案。
有時候,我們對于一個要解決的問題,可能并沒有真正理解問題的本質,可能問題本身并不是一個問題,或者這個問題在很多年之前被人已經發現了,這樣的情況在科研界是很容易出現的。比如之前吵得沸沸揚揚的關于一種新的特征值解法 ,陶哲軒在這一塊也犯了這樣的錯誤。對于我們普通人來說,更可能如此,一些問題只是拍腦袋想出來的,并沒有深思熟慮。
很多人曾經指出:“能夠準確地提出問題,就相當于這個問題已經解決了一半。”因此,定義問題是解決問題的首要環節。
問題的定義主要有兩個部分,分別是確定目標和劃定邊界。我們的目標應該是可以量化并且可以實現的,目標可能有一個目標,可能有多個目標,也可能是一個目標下有很多子目標。其次,我們需要劃定邊界,因為一個問題受到的影響因素有很多,我們需要做出取舍,找出主要矛盾,舍棄次要矛盾。這對于我們來說,實際上都是非常容易讓我們頭大的事情。
但幸運的是,對于廣大技術工作者或數學建模競賽愛好者來說,上述問題基本上都是現成的,都是由相關機構或者相關人員經過深思熟慮后考慮的問題,我們只需要好好思考模型,去解決問題就好了。
收集數據,我認為是另外一個老大難的問題。很多人參與過科研項目或者數學建模競賽的人都知道,有時候,即是是一個非常簡單的問題,或者是一個非常成熟的問題,沒有數據,什么都是白搭,巧婦難為無米之炊。因此,我們需要開動腦筋,發揮自己和合作伙伴的優勢,爭取擴大自己的數據使用權和數據獲取渠道能力。同時,收集數據對定義問題也很重要 :
在定義問題的同時,還需要收集相應的數據。收集數據可以驗證對問題的定義是否合理。
我們可以通過問題的指導下去收集可能可以解決問題所需要的數據,同時我們也可以根據數據收集的程度,反過來看是否需要修改問題的影響因素或邊界條件。
數據的收集通常是一個很繁瑣的工作,我們往往希望乞求于有專業的組織或者個人可以給我們分享數據。某些數據我們可以根據網上現存的,如國家統計局的數據,而更多時候,我們只能通過自己收集,需要通過大量的調研、收集和整理。現在很多大企業越來越注重數據的收集、清洗、存儲,在未來大數據時代中,數據驅動和“以數據為王”會成為很多企業堅定發展的目標。
有時候因為數據收集上存在一定的差距,因此在很多和建模相關的競賽中都給與數據,這樣可以盡最大可能保證比賽更多地是在比較模型的優劣。因為有時候,收集到一份非常有意義并且是獨家的數據,哪怕使用最簡單的圖表分析和描述性統計,也能做出較為有意義的解釋。目前在數學建模競賽中,全國大學生數學建模競賽和全國研究生數學建模競賽是兩個相對數據上保證公平的比賽,建議大家多多參與。
好了以上是關于定義問題和收集數據環節的解讀,下面我們可以聊聊其他環節。
下面的兩個環節可以放在一起來說,即數學建模和模型求解。在數學建模競賽中,這個對應的環節是模型建立與求解,也是最為核心的步驟。同時,這應該是我們廣大看這個問題的人,最為關心的問題,即我應該如何建模,并且模型應該如何進行求解。
在前面我們已經說過 :
數學模型是利用系統化的符號和數學表達式對間題的一種抽象描述。數學建模可看作是把問題定義轉換為數學模型的過程。
大家可以回到文章中的最前面去閱讀關于數學建模的全部敘述,這里就不再重復,總而言之,這可能是對于很多本科學生甚至高中學生來說,可能第一次接觸數學建模,會覺得這是一個“骯臟”的事情。因為種種的假設以及原理不清楚、不明顯,導致不覺得這是一個完美的、普世的。尤其是剛剛學完高中物理或者數學的同學,會覺得一切都是完美的、精確的。可能認為解題僅僅是高考那樣,寫出詳細解答過程,得出答案即可。但事實上,我們閱讀很多數模相關的論文,其中處處充滿了妥協,特定的、理想化的、某一類的、近似的等不完美的詞匯出現在模型的建立過程中,對于低年級的學生來說,需要適應這種過程的轉變。我們只能盡自己最大的努力,讓模型可以更加接近實際,讓模型的價值體現出來。
下面談談模型的求解部分。對于模型的求解這一部分,我同樣引用了一段話 :
數學模型中通常包含一些未知變量,如決策變量,需要通過模型求解來獲得其(最優)取值。模型求解就是為了找出一組滿足所有約束條件,同時使得目標函數值為最優的決策變量取值。
一般而言,模型的求解主要有以下兩種形式 :
1.確定可行解的范圍,在該范圍中通過某種方法尋找最優解。2.找到一個可行解,通過某種方法逐步對其進行優化,直到無法優化為止。
從上述的兩種求解策略中,我們可以感受到計算的工作量巨大。因此,我們是很難使用草稿紙去進行計算出一個結果。這種使用計算機進行計算的方式,在大學以前,大家很少有機會去嘗試。因此一般而言,有一個稍微痛苦的適應過程。在計算模型的工具的選擇上,從是否要編程的角度來說,可以分為按鈕式操作和編程式操作(現在很多軟件同時支持這兩種操作,我只考慮大家更加習慣傾向的使用方式)。從是否商業化的角度可以分為商業軟件和開源軟件,在下面我們可以簡單舉幾個例子:
1.MATLAB(編程操作 商業軟件)2.Python(編程操作 開源軟件)3.R(編程操作 開源軟件)4.SPSS(按鈕操作 商業軟件)5.SAS(編程操作 商業軟件)6.Julia(編程操作 開源軟件)7.STATA(按鈕操作 商業軟件)8.Eviews(按鈕操作 商業軟件)9.Origin(按鈕操作 商業軟件)10.Wolfram(編程操作 商業軟件)11.Excel(按鈕操作 商業軟件)
實際上還有非常多的工具這里無法一一列舉。大家可以根據自己的實際需要進行學習,可能是因為自己在學校選修了某一門語言,或者因為某個項目的契機剛好快速學習了某種語言,總之自己喜歡哪個,想上手哪個就用哪個。到了后期,因為自己的專業需求或者因為該領域的老師建議,再做出更加具體的選擇。
從上面的介紹可以看出,很多軟件的主要還是通過按鈕操作,因此對于我們廣大文科、經管類學生來說,嘗試使用數學模型去解決一些問題的門檻,也沒有那么高。對于理工科學生來說,學習一些語言的同時,實際上已經順手掌握了一門可以用來求解模型的語言。
對于求解的結果,我們可以使用不同的形式進行表達,可以使用干巴巴的數據、可以使用一系列的表格、也可以使用不同的圖表進行可視化表示。在今天大數據時代,數據可視化越來重要。由于海量的數據對于決策者來說很容易摸不清頭腦。這時候有一張較為清晰的圖表,對于決策者來說,更加容易理解當前的結果并做出合理的判斷。
對于市面上存在的林林總總的使用教程,雖然有些書寫的不錯,但是并不是最好的。最好的教程永遠都是help文件或者技術文檔。比如MATLAB的help文件幾乎介紹了所有你可能用到的功能,并且給予了代碼示例 ,從下圖我們可以看出,幫助文檔非常全,基本上過一遍自己需要了解的內容,就可以上手開始了:
MATLAB幫助文檔菜單
比如我想學習多元線性回歸并且想繪制回歸曲線出來,我們查閱了MATLAB的幫助文檔,得到下面的這種求解辦法 :
load carsmallYear = categorical(Model_Year);tbl = table(MPG,Weight,Year);mdl = fitlm(tbl,'MPG ~ Year Weight^2');plot(mdl)
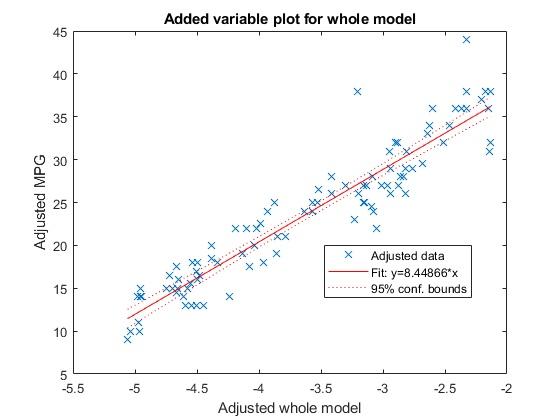
MATLAB繪制出來的曲線
我們可以通過這種辦法,一點點地去了解一個語言。其他的語言也是類似,比如你想使用Python下的可視化包Matplotlib 或者Seaborn ,你也可以去相關的官網去了解如何使用。這可能比你買書后,再去一頁頁翻書,效率要高得多。R語言也是進行類似操作。
用一句話總結,想學什么包,就去什么包的官網或者開源組織上去圍觀學習一圈,這樣應該是學習使用這種包的一種比較有效率的方法。
對于文科學生來說,在做一些簡單的統計模型或者計量模型的時候,可能會猶豫到底是使用SPSS/SAS/STATA/Eviews中的哪一種好,畢竟由于大體都是按鈕式或者編程不是那么復雜,因此主要還是應用應該更有針對性,人大經濟論壇上有一篇分析以上四種工具的比較文 ,我覺得還不錯。
還有我們應該稍微注意下商業軟件的版權問題,我在這里還是不建議大家使用盜版軟件。很多開源軟件如Python和R現在已經是非常強有力的模型求解武器。對于在校學生來說,MATLAB在很多學校也有開放正版軟件的使用許可,對于參加全國大學生數學建模競賽的同學,也有申請免費使用的許可。大家可以根據自己學校的特色和傾向性對工具進行選擇。
以上稍微介紹了一下如何快速上手相關工具的經驗分享,可能有點和這個問題的主題并不完全相關,但是我覺得作為很多同學的疑惑,在這里很有必要說清楚。
最后關于大學生數學建模競賽,我適當補充一些對于剛剛開始嘗試這項比賽的選手的做題的辦法,我將其稱之為黑箱理論 。因為對于大學生來說,短期內徹底明白一個比較熱門的模型是很困難的,尤其是這道題目并不是我們專業相關的。我有一個比較生動的例子:你需要學會使用錘子,但是你暫時還不需要學會造錘子!
關于一些較為基礎的模型,大家可以去我的朋友的CSDN下的博客 上進行學習。關于數學建模競賽相關的問題,大家可以關注我的回答集合 ,希望這個回答可以幫助到大家。其實挺希望未來的學習門檻可以繼續降低,最好可以游戲化,比如Python學習上就有類似的工作 。
關于模型解決問題這一流程中最關鍵的問題敘述完畢!下面我們來談一談優化后分析(靈敏度分析)這一步。
這一步說老實話,很多人都搞不清楚,也對這個問題避而不談,在數學建模競賽中,大家在這個環節上一般草草了事或者套一套模板,或者直接避而不談。這里我稍微談一談吧。
一般而言,我們所求解的結果是一個非常理想化的結果,即是建立在一個合理的假設后的模型,并且其環境變量是準確的或較優的。在優化后分析這一步,我們假設模型是合理的,而重點分析環境變量的取值,和在環境變量下取值的變動進行討論和分析。關于環境變量的敘述見下 :
環境變量是我們對未來環境狀態的一種估計,因而不可避免地會存在一定的誤差。同時,在方案實際執行過程中,環境變量的取值還可能會發生不同程度的變化。而環境變量取值的變化,可能會導致模型的最優解和目標函數的最優值發生變化。如果依據當前模型的最優解做出決策,就存在一定程度風險。為了緩解或是避免環境變化可能造成的風險,在提出決策建議前還需要進行優化后分析。
以上是環境變量的解釋,以及環境變量對模型的影響。下面是一個對優化后分析的一種定義 :
優化后分析也被稱為敏感性分析,即分析模型最優解和最優值對某一個或多個環境變量發生變化的敏感程度,是一種評估候選方案風險的不確定性分析方法。敏感性分析有兩種常見的方法:一是分析在最優解(即最優方案保持不變)的情況下,各個環境變量允許變動的范圍,稱為可變范圍;二是使環境變量在特定范圍內(通常是在當前估計值的周圍)變動,觀察相應的模型輸出變化的情況。
一般而言,在數學建模競賽中,大家在做敏感性分析時,傾向使用圖表來描述一個模型輸出情況。這樣的原因主要有以下幾點:第一,大家一般在做敏感性分析時,到了比賽的末尾階段,可能大家多多少少感到時間上不夠用。一般決定做敏感性分析的隊伍,基本上都是要決定沖擊國家一等獎的隊伍,更多的隊伍選擇放棄這個部分,直接對文章進行收尾工作。所以,對非常有限的條件進行“調參”,在這個基礎上,把一系列的輸出用圖像的形式進行表示,這樣不僅節省時間,而且由于圖像直觀易懂,評委可以馬上清楚模型在環境的影響下會如何出現變化。
對于環境的可變范圍,也有一定的講究 :
由于實際環境固有不確定性,導致決策不可避免地會存在一定程度的風險,敏感性分析有助于降低這種風險。一般而言,環境變量可變范圍越大,則實際超出該范圍的可能性就越小,對應的風險也就越小。反之,可變范圍越小,則實際超出該范圍的可能性就越大,對應的風險也就越大。
對于模型的解而言,可能最優解經過敏感性分析后發現其環境變量的可變程度較小,因此雖然結果較好,但是十分受到環境的制約,存在較大的風險。而一些輸出可能結果不如最優解,但其環境適應能力較好,對于不同的決策者會有不同的選擇。因此雖然說在數學建模競賽中,我們為了趕時間可以不進行這個分析,但是在日常生活中,做相關分析時,可不能忘記了,其存在的風險可能會真正影響到我們的生活。我們熟悉的投資組合模型就是利用了這一思想。
下面我們來談一談模型檢驗。模型的檢驗相當于是一項工程的驗收階段,由于我們的模型是對現實世界的一種抽象表示,一種高度概括,其合理性是由我們對模型的相關假設是否正確、是否反映現實所確定。由于我們知道,所有的模型都不是完美的,都存在一定的“失真”,因此在模型使用之前,我們需要通過一些手段,對模型進行檢驗,來確保我們的模型可以真正地應用到現實問題上去。下面是模型檢驗的定義 :
把模型求解和分析得到的結果與所研究的實際問題進行對比分析,以檢驗模型的合理性,稱為模型檢驗。如果檢驗發現模型結果與實際不符,則應該修正假設或是改換其他方法重新構建模型。通常一個模型需要經過多次反復修改,才能得到令人滿意的結果。
以上是模型檢驗的定義,在數學建模競賽或者很多模型類比賽的流程中,這一步往往很少單獨拿出來作為一個流程進行分析。而是模型的建立與求解中,間接地進行模型的檢驗了。比如我們會將一些歷史上的數據代入模型來檢驗模型的準確性,或者根據生活常識來判斷模型的計算合理不合理。對于實在是沒有數據的情況下,我們可以做仿真,生成大量的數據,來通過這些數據對模型進行驗證分析。
在做出模型檢驗時,我們一般默認我們的模型是好用的,結果是精確的,然后我們通過不同的案例,不同的輸入來驗證這個模型是否正確。通常我們對于模型的檢驗的常用方法有以下三種 :
1.第三方測試,這一點通常是數學建模競賽或相關賽事沒有辦法做到的模型檢驗的方法,因為我們在比賽完了之后,才有所謂的第三方評委幫我們進行閱卷。我們在進行模型驗證時,最好找一個從來都沒有參與過模型構建的人,以他自己的視角重新檢驗問題的定義和模型的構建是否合理,或者從不同的角度,再構建一個或多個新模型,并將其結果與原模型進行對比。模型越多,出現同樣錯誤的概率越小。從以上文字我們可以看出一件非常有意思的事實,由于對于我們每個人來說,數學建模競賽是無法做到第三方測試的,但是對于組委會來說,則是一個沒有標的,即無監督的大型第三方測試。意思就是說,不同的參賽作品互為第三方測試,最終組委會在所有的模型中選擇兩個最好的模型授予“高教社杯”和“MATLAB創新獎。”2.回溯檢驗,使用歷史數據重現過去來檢驗所構建的模型在歷史環境中的應用效果。雖然模型的應用場景是未來,但是未來沒有來臨,我們無法進行對比分析。但在很多的應用中,已經積累了大量的歷史數據,可以用來模型的檢驗。雖然過去不一定代表未來,但是如果模型在已經知道明確結果的過去都無法給出一個令人滿意的結果,就很難說服決策者相信這個模型能夠在一切都還未知的未來,會給我們帶來預期的使用效果。在數學建模競賽中,回溯檢驗是一個我們較為常用的檢驗方法,我們通常可以帶入一些已經有的數據對模型進行檢驗。比如2017年的數學建模國賽A題,第一問和第二三問就是一個內容,兩個方向的過程。對于絕大多數數據驅動類的問題,都可以采用回溯檢驗對模型進行驗證。3.計算機仿真,如果我們沒有足夠的歷史數據用來進行回溯檢驗,可以嘗試利用計算機來對模型的運行環境進行模擬仿真,生成大量的測試數據,并利用這些數據對模型進行驗證分析。如我們較為熟悉的蒙特卡洛模擬就是一個常用的仿真方法。一般而言,仿真常出現在數據量不足或不給數據的比賽,如美國大學生數學/交叉學科建模競賽,通常就要通過對模型進行仿真來驗證模型的合理性,如2019年D題有關盧浮宮逃生路線設計,就需要使用這種方法來對模型進行驗證。
以上是關于模型檢驗的介紹,下面是有關提出建議、做出決策和方案實施與觀察的介紹。提出建議、做出決策和方案實施是一次基于模型解決問題的最后一步。提出建議主要是根據優化后分析和模型檢驗后的理想模型和備選模型給出建議,以及這些模型背后的某種決策方案進行建議。之后則需要解決問題的人對這些模型進行選擇,即“選擇應該使用哪一把螺絲刀進行工作,”,對于不同性格的決策者,可能會對某些模型、對某些結果存在一定的偏好,我們應該對這種非理性的因素給予尊重,決策分為單目標決策和多目標決策。最后則是方案的實施和觀察,這一步則是把我們的建立的模型和根據模型做出的結果應用到現實生活中去,如果一切正常,并且在未來我們所經歷的事情恰好就是我們模型所預見的那樣,那么這個模型可以繼續使用。如果存在較大的偏差,則需要去發現是哪里出現了問題,一般主要的問題來自于問題的定義、問題的假設、數據的收集、環境變量的估計、以及最重要的模型的建立,我們需要逐一排查,發現問題后,需要重新再來一遍這樣的流程。
幸運的是,大多數的數學建模工作是到不了這一步的,我們不需要擔心我們的工作前功盡棄。一般在做完敏感性分析之后,便永遠地躺在論文里。只有極少數優秀的、并且實用的模型,才有機會放在決策者的桌上,供決策者選擇并且應用。這里需要注意的是,目前可能應用在實際生活中的模型,可能并不是這個世界上最先進、最好用的模型,但一定是經過了時間的洗禮,默默無聞地幫助了成千上萬的人。
以上,便是對數學建模的過程(生命周期)進行了一個較為完整清晰的敘述,下面我們來談一談第二個議題,即它可以解決哪些問題。
2. 數學建模可以解決哪些問題?
實際上我覺得這個問題太大了,我沒有資格來回答這個問題,因為說句實話,隨著數學、統計學和計算機科學的蓬勃發展,基本上每一門學科都開始或者嘗試開始使用數學建模的方法研究本學科。在宏觀的學科上,比如自然科學(數學、物理學、化學、生命科學、計算機科學、環境科學、地球科學、心理與認知科學等)、工程學(電子工程、電氣工程、機械工程、土木工程、軟件工程、汽車工程、人工智能、材料科學與工程等)、社會科學(政治學、經濟學、管理學、教育學、社會學等)其中都有數學建模的影子,比如某門學科前面帶上計算、計量、信息、分析、優化、運籌、統計這樣詞匯的學科或科目,一般都涉及了數學建模。比如計算物理、計算化學、計算數學、生物信息學、計量經濟學、商業分析等。對于不同專業的同學對于數學建模的理解深度需要不同,我可以做個恰當的比喻。學數學的同學,需要會造錘子,也會使用錘子,并且造錘子的時間可能比使用錘子的時間多很多。廣大理工科專業的同學,需要看過造錘子,但是自己只要會用錘子就行了,并且應該是最會使用錘子的一類人。廣大社會科學專業的同學,只需要使用錘子,并且只是偶爾使用錘子就行了。
如果大家想要了解一些數學建模較為簡單的案例,可以買一本書,這本書是姜啟源和謝金星老師所寫,叫做《數學模型》(第五版) ,這本書也可以基本上認為是全國大學生數學建模競賽的半官方讀物。如果用心閱讀此書,并且在參加數學建模競賽,尤其是全國大學生數學建模競賽中,這本書一定要備在身上,比如在2017年國賽A題和2019年國賽A題的問題,有一定程度上參考這本書上的模型。比如這本書第六章代數方程與差分方程模型中的CT技術的圖像與重建,就是2017年國賽A題的最基礎的模型,在這本書的基礎之上進行學習和文獻查閱,會提高很多效率。還有第五章中的香煙過濾嘴的作用,可以類比2019年高壓油管的模型建立。所以不管是從感興趣的角度還是從比賽功利的角度,這本書都是值得學習一下的。下面我把這本書的目錄給大家搬運一下,參與過數學建模競賽的同學們,應該會看到很多熟悉的影子:
第一章 建立數學模型1.1從現實對象到數學模型1.2數學建模的重要意義1.3建模示例之一包餃子中的數學1.4建模示例之二路障間距的設計1.5建模示例之三椅子能在不平的地面上放穩嗎1.6數學建模的基本方法和步驟1.7數學模型的特點和分類1.8怎樣學習數學建模——學習課程和參加競賽第二章 初等模型2.1雙層玻璃窗的功效2.2劃艇比賽的成績2.3實物交換2.4汽車剎車距離與道路通行能力2.5估計出租車的總數2.6評選舉重總冠軍2.7解讀CPI2.8核軍備競賽2.9揚帆遠航2.10節水洗衣機第三章 簡單優化模型3.1存貯模型3.2森林救火3.3傾倒的啤酒杯3.4鉛球擲遠3.5不買貴的只買對的3.6血管分支3.7冰山運輸3.8影院里的視角和仰角3.9易拉罐形狀和尺寸的最優設讓第四章 數學規劃模型4.1奶制品的生產與銷售4.2自來水輸送與貨機裝運4.3汽車生產與原油采購4.4接力隊選拔和選課策略4.5飲料廠的生產與檢修4.6鋼管和易拉罐下料4.7廣告投入與升級調薪4.8投資的風險與收益第五章 微分方程模型5.1人口增長5.2藥物中毒急救5.3捕魚業的持續收獲5.4資金、勞動力與經濟增長5.5香煙過濾嘴的作用5.6火箭發射升空5.7食餌與捕食者模型5.8賽跑的速度5.9萬有引力定律的發現5.10傳染病模型和SARS的傳播第六章 代數方程與差分方程模型6.1投入產出模型6.2CT技術的圖像重建6.3原子彈爆炸的能量估計與量綱分析6.4市場經濟中的蛛網模型6.5減肥計劃——節食與運動6.6按年齡分組的人口模型第七章 離散模型7.1汽車選購7.2職員晉升7.3廠房新建還是改建7.4循環比賽的名次7.5公平的席位分配7.6存在公平的選舉嗎7.7價格指數7.8鋼管的訂購和運輸第八章 概率模型8.1傳送系統的效率8.2報童的訣竅8.3航空公司的超額售票策略8.4作弊行為的調查與估計8.5軋鋼中的浪費8.6博彩中的數學8.7鋼琴銷售的存貯策略8.8基因遺傳8.9自動化車床管理第九章 統計模型9.1孕婦吸煙與胎兒健康9.2軟件開發人員的薪金9.3酶促反應9.4投資額與生產總值和物價指數9.5冠心病與年齡9.6鯨蟲分類判別9.7學生考試成績綜合評價9.8艾滋病療法的評價及療效的預測第十章 博弈模型10.1點球大戰10.2擁堵的早高峰10.3“一口價”的戰略10.4不患寡而患不均10.5效益的合理分配10.6加權投票中權力的度量
通過這本書我們可以看到數學建模在各個領域的簡單應用,至于更深層次的應用,我覺得各行業的從業者,都可以單獨開一個新的問題進行討論了。在教學的環節中,能理解到上述層次一般上是夠用了。下面回答最后一個,也是最為使用的問題:目前有哪些和數學建模相關的競賽?
3. 目前有哪些和「數學建模」相關的競賽?
這是一個非常好的問題,也應該是這篇回答最為實用的問題,作為一名學科競賽指導老師,在這個領域有自己的心得體會。目前由于人工智能和數學建模是強相關,本質上人工智能的分支是很多統計模型的合集。因此這一兩年數學建模類的競賽越來越火熱。我把數學建模競賽主要分為三類:
- 直接冠以「數學建模」在競賽名字上的比賽,也就是狹義數學建模競賽。
- 與數學建模間接相關的比賽,如人工智能、數據分析等競賽平行競賽,以及將數學建模利用到自己各個專業中的比賽,如iGEM,以及各種創新創業類、學術作品比賽中間接用到數學建模方法的,如挑戰杯、互聯網 、節能減排等,這我將其稱為廣義數學建模競賽。
一般我們大多數學生參加的數學建模競賽為狹義數學建模競賽,我一篇文章數學建模競賽的一些心得體會(關于每年的比賽) 中有對一年所有狹義的數學建模競賽進行梳理和難度分析。這里我僅列舉我國官方組織舉辦的數學建模競賽 :
1.全國大學生數學建模競賽(簡稱國賽)2.“深圳杯”數學建模挑戰賽(簡稱深圳杯)3.中國研究生數學建模競賽(簡稱研賽)
以上是我們我們國家官方組織舉辦的比賽,特別注意的是國賽和研賽在上海市落戶加分中是被認可的。國賽是目前發展最完善、影響力最大、參與人數最廣、并且規則最為嚴格的比賽。深圳杯是一個競爭最為激烈,參賽周期最長,含金量最高,并且在一定程度上解決實際問題的比賽。想要學習數學建模或者查閱數學建模優秀論文,可以去中國大學生在線-數學建模板 塊進行學習。研賽也是是目前研究生參與人數最多的比賽之一。
除了大學生和研究生的數學建模競賽,高中生的數學建模競賽也有一定程度的發展,分別是丘成桐科學獎和美國高中生數學建模競賽,由于參與人數較少,并且高中生的知識儲備大多不足,并且大多精力有限,這里不展開介紹。
關于廣義數學建模競賽,真的是無窮無盡的。我覺得現在凡是掛上人工智能、數據分析、數據挖掘等名頭的都可以算作這一類比賽,由于比賽很多,我在知乎上找了一個不錯的問題:國內外有哪些數據分析相關的競賽比賽網站? ,大家可以進行參考。
關于自己各個學科、各個領域的學習(競賽)中,大家在參與的時候,不妨思考下,到底能不能用到數學建模的相關知識,是一定要用?還是用了之后會錦上添花?
這個問題,我想在本回答的最后,留給各大讀者朋友們!大家可以在評論區進行留言,一起討論。
如果喜歡,歡迎點贊 收藏哦~
