不看就虧系列!這里有完整的 Hadoop 集群搭建教程,和最易懂的 Hadoop 概念!- 附代碼


作者 | chen_01_c
責編 | Carol
來源 | CSDN 博客
封圖 | CSDN付費下載于視覺中國
hadoop介紹
Hadoop 是 Lucene 創始人 Doug Cutting,根據 Google 的相關內容山寨出來的分布式文件系統和對海量數據進行分析計算的基礎框架系統,其中包含 MapReduce 程序,hdfs 系統等![它受到最先由 Google Lab 開發的 Map/Reduce 和 Google File System(GFS) 的啟發。]
Hadoop實現了一個分布式文件系統(Hadoop Distributed File System),簡稱HDFS。HDFS有高容錯性的特點,并且設計用來部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)來訪問應用程序的數據,適合那些有著超大數據集(large data set)的應用程序。HDFS放寬了(relax)POSIX的要求,可以以流的形式訪問(streaming access)文件系統中的數據。
Hadoop的框架最核心的設計:HDFS 和mapreduce
HDFS:為海量數據提供存儲
MapReduce: 為海量數據提供了計算cluster:集群
LB:負載均衡
LVS SLB HAPROXY,nginx
HA:高可用
MHA,keepalived,hearebeat
HPC、Hadoop:大批量的計算輔助存儲和運算
什么是分布式:分散的

Hadoop的集群優點
Hadoop是一個能夠對大量數據進行分布式處理的軟件框架。Hadoop 以一種可靠、高效、可伸縮的方式進行數據處理。
Hadoop 是可靠的,因為它假設計算元素和存儲會失敗,因此它維護多個工作數據副本,確保能夠針對失敗的節點重新分布處理。
Hadoop 是高效的,因為它以并行的方式工作,通過并行處理加快處理速度
Hadoop 還是可伸縮的,能夠處理 PB 級數據。
PB級別的數據換算成G?
IPB=1024TB
1TB=1024G
Hadoop 依賴于社區服務,因此它的成本比較低,任何人都可以使用。
Hadoop是一個能夠讓用戶輕松架構和使用的分布式計算平臺。用戶可以輕松地在Hadoop上開發和運行處理海量數據的應用程序。它主要有以下幾個優點:
-
高可靠性:hadoop 按位存儲和處理數據的能力值得人們信賴
高擴展性:節點比較多,方便計算和分配數據。
什么是節點?
節點是一個術語,代指一類設備.他們可以是主機(pc),服務器,也可以是構成傳輸網絡的交換機,路由器,防火墻等等.
高效性:Hadoop能夠在節點之間動態地移動數據,并保證各個節點的動態平衡,因此處理速度非常快。
容錯性:Hadoop能夠自動保存數據的多個副本,并且能夠自動將失敗的任務重新分配。
raid 容錯性是什么意思,raid幾沒有容錯性?raid 幾有容錯性。
低成本:與一體機、商用數據倉庫以及QlikView、Yonghong Z-Suite等數據集市相比,hadoop是開源的,項目的軟件成本因此會大大降低
注意:hadoop框架開發語言:java,在linux上運行效果比較理想。
官網:http://hadoop.apache.org/
關于hadoop的相關概念
1、分布式存儲:
linux存儲有哪些?
答:NFS, NAS, HDFS,MFS
命名空間
namespace:在分布式存儲系統中,分散在不同節點中的數據可能屬于同一個文件,為了組織眾多的文件,把文件可以放到不同的文件夾中,文件夾可以一級一級的包含。我們把這種組織形式稱為命名空間(namespace)。命名空間管理著整個服務器集群中的所有文件。命名空間的職責與存儲真實數據的職責是不一樣的。負責命名空間職責的節點稱為主節點(master node),負責存儲真實數據職責的節點稱為從節點(slave node)。
主從節點:
主節點負責管理文件系統的文件結構,從節點負責存儲真實的數據,合稱為主從式結構(master-slaves)。
用戶操作的時候,也應該是先和主節點打交道, 查詢數據在那些從節點上, 然后再從從節點讀取數據。有的時候為了加快用戶的訪問速度,會把整個命名空間信息都放在內存當中、當存儲文件越多時,我們主節點就需要越多的內存空間。
打開一個文件是先加載到哪里?
答:內存
我們為什么用筆記本打不開一個2T大小的文件?
答:內存太小
2、Block
在從節點存儲數據時,有的原始數據文件可能很大,有的可能很小,大小不一的文件不容易管理,那么可以抽象出一個獨立的存儲文件單位,稱為塊(block)。
問題:如果我的硬盤有500G,現在還剩200G ,但是我創建文件的時候提示我硬盤空間不足?
答:一般情況是因為inode號不足
3、容災
數據存放在集群中,可能因為網絡原因或者服務器硬件原因造成訪問失敗,最好采用副本(replication)機制,把數據同時備份到多臺服務器中,這樣數據就安全了,數據丟失或者訪問失敗的概率就小了。
4、異地容災?
答:不同的地域,構建一套或者多套相同的應用或者數據庫,起到災難后立刻接管的作用。
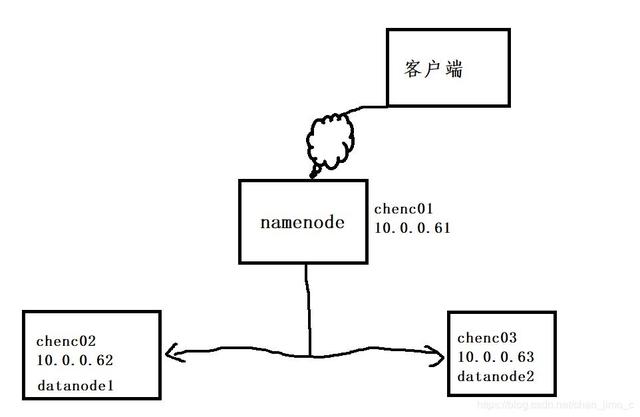
在 hadoop 中,分布式存儲系統稱為 HDFS(hadoop distributed file system)。其中,主節點稱為名字節點(namenode),從節點稱為數據節點(datanode)。
流程:
1:首先,客戶端請求查看數據,請求先訪問namenode
2:nomenode根據你的需求,告訴你數據存儲在那些datanode上
3:客戶端直接和從節點聯系,獲取數據

分布式計算
對數據進行處理時,我們會把數據讀取到內存中進行處理。如果我們對海量數據進行處理,比如數據大小是 100GB,我們要統計文件中一共有多少個單詞。要想把數據都加載到內存中幾乎是不可能的,稱為移動數據。
那么是否可以把程序代碼放到存放數據的服務器上呢?因為程序代碼與原始數據相比,一般很小,幾乎可以忽略的,所以省下了原始數據傳輸的時間了。現在,數據是存放在分布式文件系統中,100GB 的數據可能存放在很多的服務器上,那么就可以把程序代碼分發到這些服務器上,在這些服務器上同時執行,也就是并行計算,也是分布式計算。這就大大縮短了程序的執行時間。我們把程序代碼移動數據節點的機器上執行的計算方式稱為移動計算。
分布式計算需要的是最終的結果,程序代碼在很多機器上并行執行后會產生很多的結果,因此需要有一段代碼對這些中間結果進行匯總。Hadoop中的分布式計算一般是由兩階段完成的。
第一階段負責讀取各數據節點中的原始數據,進行初步處理,對各個節點中的數據求單詞數。然后把處理結果傳輸到第二個階段,對個節點結果進行匯總,產生最終結果。
在hadoop中,分布式計算部分稱為MapReduce。
MapReduce 是一種編程模型,用于大規模數據集(大于1TB)的并行運算。概念”Map(映射)“和”Reduce(歸約)”,和它們的主要思想,都是從函數式編程語言里借來的,還有從矢量編程語言里借來的特性。它極大地方便了編程人員在不會分布式并行編程的情況下,將自己的程序運行在分布式系統上。

分布式計算角色
主節點:作業節點(jobtracker)
從節點:任務節點(tasktracker)
在任務節點當中,運行第一階段的代碼稱為map任務(map task ) ,運行第二階段代碼稱為 reduce任務(reduce task)
名詞解釋:
1)hadoop: apache 開源的分布式框架
2)HDFS:hadoop的分布式文件系統
3)NameNode: Hadoop HDFS 元數據主節點服務器,負責保存datenode文件存儲元數據信息,這個服務器時單點的。
4) obtracker: hadoop的map/reduce調度器,負責與任務節點通信分配計算任何并跟蹤任務進度,這個服務器也是單點的。
5)DataNode: Hadoop的數據節點,負責存儲數據
6)tasktracker: hadoop的調度程度,負責map和reduce的任務的啟動和執行
hadoop集群搭建
1)環境
配好IP,關閉iptables, 關閉selinux,配置hosts
[root@ chenc01 ~]# service iptables stop[root@ chenc01 ~]# setenforce 0[root@ chenc01 ~]# vim /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain610.0.0.61 chenc0110.0.0.62 chenc0210.0.0.63 chenc03
2)創建普通用戶
三臺服務器上都要創建普通用戶,hadoop,配置密碼:123456
[root@ chenc01 ~]# useradd -u 8000 hadoop ; echo 123456 | passwd --stdin hadoop更改用戶 hadoop 的密碼 。passwd: 所有的身份驗證令牌已經成功更新。
3) 設置namenode
設置namenode能夠無密鑰登錄另外兩臺服務器
[root@ chenc01 ~]# ssh-keygenGenerating public/private rsa key pair.Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'.Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa.Your public key has been saved in /root/.ssh/id_rsa.pub.The key fingerprint is:f1:7c:f6:6c:81:f5:a6:2a:74:d1:f2:95:50:38:ad:6f root@chenc01.localdomainThe key's randomart image is: --[ RSA 2048]---- | . || . || . .= .|| o .o.|| S o o.o|| .o.o.E || . . * || . o || .. | ----------------- [root@ chenc01 ~]# ssh-copy-id root@10.0.0.62The authenticity of host '10.0.0.62 (10.0.0.62)' can't be established.RSA key fingerprint is 9b:57:b9:86:84:90:a4:4b:44:3e:18:9f:8a:29:6f:e5.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added '10.0.0.62' (RSA) to the list of known hosts.root@10.0.0.62's password: Now try logging into the machine, with "ssh 'root@10.0.0.62'", and check in: .ssh/authorized_keysto make sure we haven't added extra keys that you weren't expecting.[root@ chenc01 ~]# ssh-copy-id root@10.0.0.63The authenticity of host '10.0.0.63 (10.0.0.63)' can't be established.RSA key fingerprint is 9b:57:b9:86:84:90:a4:4b:44:3e:18:9f:8a:29:6f:e5.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added '10.0.0.63' (RSA) to the list of known hosts.root@10.0.0.63's password: Now try logging into the machine, with "ssh 'root@10.0.0.63'", and check in: .ssh/authorized_keysto make sure we haven't added extra keys that you weren't expecting.# 測試(是否能登錄成功[root@ chenc01 ~]# ssh 10.0.0.62Last login: Fri Nov 29 17:15:15 2019 from 10.0.0.1
4)安裝jdk
[root@ chenc01 ~]# rpm -ivh jdk-8u131-linux-x64_.rpm Preparing... ########################################### [100%] 1:jdk1.8.0_131 ########################################### [100%]Unpacking JAR files... tools.jar... plugin.jar... javaws.jar... deploy.jar... rt.jar... jsse.jar... charsets.jar... localedata.jar...# 修改/etc/profileexport JAVA_HOME=/usr/java/jdk1.8.0_131/export JAVA_BIN=/usr/java/jdk1.8.0_131/bin/export PATH=${JAVA_HOME}/bin:$PATHexport CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar# 加載[root@ chenc01 ~]# source /etc/profile# 查看java版本[root@ chenc01 ~]# java -versionjava version "1.8.0_131"Java(TM) SE Runtime Environment (build 1.8.0_131-b11)Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
問題:source 在數據庫里還可以用來做什么?
答:導入
5)在另外兩個節點安裝java/jdk
[root@ chenc02 ~]# rpm -ivh jdk-8u131-linux-x64_.rpm Preparing... ########################################### [100%] 1:jdk1.8.0_131 ########################################### [100%]Unpacking JAR files... tools.jar... plugin.jar... javaws.jar... deploy.jar... rt.jar... jsse.jar... charsets.jar... localedata.jar...# 修改/etc/profileexport JAVA_HOME=/usr/java/jdk1.8.0_131/export JAVA_BIN=/usr/java/jdk1.8.0_131/bin/export PATH=${JAVA_HOME}/bin:$PATHexport CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar# 加載[root@ chenc02 ~]# source /etc/profile# 查看java版本[root@ chenc02 ~]# java -versionjava version "1.8.0_131"Java(TM) SE Runtime Environment (build 1.8.0_131-b11)Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
6)安裝namenode
Hadoop 安裝目錄:/home/hadoop/hadoop-3.13 使用 root 帳號將 hadoop-3.1.3.tar.gz 上傳到服務器,并且放到/home/hadoop下!
-
創建dfs和tmp
[root@ chenc01 ~]# su - hadoop[hadoop@ chenc01 ~]$ mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp[hadoop@ chenc01 ~]$ rz[hadoop@ chenc01 ~]$ whoami hadoop[hadoop@ chenc01 ~]$ lsdfs hadoop-3.1.3.tar.gz tmp
解壓
[hadoop@ chenc01 ~]$ tar xvf hadoop-3.1.3.tar.gz[hadoop@ chenc01 ~]$ cd hadoop-3.1.3[hadoop@ chenc01 hadoop-3.1.3]$ lltotal 200drwxr-xr-x 2 hadoop hadoop 4096 2019-09-12 12:46 bindrwxr-xr-x 3 hadoop hadoop 4096 2019-09-12 10:51 etcdrwxr-xr-x 2 hadoop hadoop 4096 2019-09-12 12:46 includedrwxr-xr-x 3 hadoop hadoop 4096 2019-09-12 12:46 libdrwxr-xr-x 4 hadoop hadoop 4096 2019-09-12 12:46 libexec-rw-rw-r-- 1 hadoop hadoop 147145 2019-09-04 17:31 LICENSE.txt-rw-rw-r-- 1 hadoop hadoop 21867 2019-09-04 17:31 NOTICE.txt-rw-rw-r-- 1 hadoop hadoop 1366 2019-09-04 17:31 README.txtdrwxr-xr-x 3 hadoop hadoop 4096 2019-09-12 10:51 sbindrwxr-xr-x 4 hadoop hadoop 4096 2019-09-12 13:08 share[hadoop@ chenc01 hadoop-3.1.3]$ cd /home/hadoop/hadoop-3.1.3/etc/hadoop/[hadoop@ chenc01 hadoop]$ pwd/home/hadoop/hadoop-3.1.3/etc/hadoop[hadoop@ chenc01 hadoop]$ lshadoop-env.sh # java的環境變量yarn-env.sh # 制定yarn框架的Java運行環境slaves # 指定datanode數據存儲服務器core-site.xml # hadoop-web界面路徑hdfs-site.xml # 文件系統的配置文件mapred-site.xml # mapreducer 任務配置文件yarn-site.xml # yarn框架配置,主要一些任務的啟動位置
修改文件
[hadoop@ chenc01 hadoop]$ vim hadoop-env.shexprot JAVA_HOME=/usr/java/jdk1.8.0_13[hadoop@ chenc01 hadoop]$ vim yarn-env.shJAVA_HOME=/usr/java/jdk1.8.0_131[hadoop@ chenc01 hadoop]$ vim slaveschenc02chenc03
備注:這個是hadoop的核心配置,這里需要配置兩屬性, fs.default.name 配置hadoop的HDFS系統命令,位置為主機的9000端口, hadoop.tmp.dir 配置haddop的tmp目錄的根位置。
[hadoop@ chenc01 hadoop]$ vim core-site.xml<configuration><property> <name>fs.defaultFS</name> <value>hdfs://chenc01:9000</value></property><property> <name>io.file.buffer.size</name> <value>131072</value></property><property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/tmp</value> <description>Abase for other tmporary directries.</description></property></configuration>
備注:HDFS主要的配置文件, dfs.http.address配置了hdfs的http的訪問位置;
dfs.replication 配置文件的副本,一般不大于從機個數。
[hadoop@ chenc01 hadoop]$ vim hdfs-site.xml<configuration><property><configuration><property> <name>dfs.namenode.secondary.http-address</name> <value>chenc01:9000</value></property><property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/dfs/name</value></property><property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/dfs/data</value></property><property> <name>dfs.replication</name> <value>2</value></property><property> <name>dfs.webhdfs.enabled</name> <value>true</value></property></configuration>
備注:這個是mapreduce任務配置文件,mapreduce.framework.name 屬性下配置yarn,
mapred.map.tasks和mapred.reduce.tasks 分別為map和reduce 的任務數。同時指定hadoop歷史服務器hsitoryserver
我們可以通過historyserver查看mapreduce的作業記錄,比如用了多少個map,用了多少個reduce,作業啟動時間,作業完成時間。默認清空下,hadoop歷史服務器是沒有啟動的,我們需要通過命令來啟動。
[hadoop@ chenc01 ~]$ /home/hadoop/hadoop-3.1.3/sbin/mr-jobhistory-daemon.sh start historyserver/home/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh: line 39: exprot: command not foundWARNING: Use of this script to start the MR JobHistory daemon is deprecated.WARNING: Attempting to execute replacement "mapred --daemon start" instead.WARNING: /home/hadoop/hadoop-3.1.3/logs does not exist. Creating.[hadoop@ chenc01 hadoop]$ vim mapred-site.xml<configuration><property> <name>mapreduce.framework.name</name> <value>yarn</value></property><property> <name>mapreduce.jobhistory.address</name> <value>chenc01:10020</value></property><property> <name>mapreduce.jobhistory.webapp.address</name> <value>chenc01:19888</value></property></configuration>
備注:yarn框架的配置,主要是一些任務的啟動位置
[hadoop@ chenc01 hadoop]$ vim yarn-site.xml<configuration><!-- Site specific YARN configuration properties --><proetry> <name>yarn.nodemanager.aux-service</name> <value>mapreduce_shuffle</value></proetry><proetry> <name>yarn.nodemanager.uax-service.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapreduced.ShuffleHandle</value></proetry><proetry> <name>yarn.resoucemanager.address</name> <value>chenc01:8032</value></proetry><proetry> <name>yarn.resourcemanager.shceduler.address</name> <value>chenc01:8030</value></proetry><proetry> <name>yarn.resourcemanager.resource-tracker.address</name> <value>chenc01:8031</value></proetry><proetry> <name>yarn.resourcemanager.admin.address</name> <value>chenc01:8033</value></proetry><proetry> <name>yarn.resourcemanager.webapp.address</name> <value>chenc01:8088</value></proetry></configuration>
datanode配置文件生成
[hadoop@ chenc01 hadoop]$ scp -r /home/hadoop/hadoop-3.13 hadoop@chenc02:~/The authenticity of host 'chenc02 (10.0.0.62)' can't be established.RSA key fingerprint is 9b:57:b9:86:84:90:a4:4b:44:3e:18:9f:8a:29:6f:e5.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'chenc02,10.0.0.62' (RSA) to the list of known hosts.hadoop@chenc02's password: /home/hadoop/hadoop-3.13: No such file or directory[hadoop@ chenc01 hadoop]$ scp -r /home/hadoop/hadoop-3.13 hadoop@chenc03:~/The authenticity of host 'chenc03 (10.0.0.63)' can't be established.RSA key fingerprint is 9b:57:b9:86:84:90:a4:4b:44:3e:18:9f:8a:29:6f:e5.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'chenc03,10.0.0.63' (RSA) to the list of known hosts.hadoop@chenc03's password: /home/hadoop/hadoop-3.13: No such file or directory
namenode格式化數據:
一般第一次的時候需要初始化,之后就不需要了
[hadoop@ chenc01 ~]$ cd /home/hadoop/hadoop-3.1.3/bin/[hadoop@ chenc01 bin]$ ./hdfs namenode -format2020-03-04 16:05:17,247 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds .2020-03-04 16:05:17,268 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 02020-03-04 16:05:17,277 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.2020-03-04 16:05:17,278 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************SHUTDOWN_MSG: Shutting down NameNode at xinsz08-1/192.168.1.18************************************************************/
查看是否生成相應的內容
[hadoop@ chenc01 ~]$ cd /home/hadoop/dfs/[hadoop@ chenc01 dfs]$ lsdata name[hadoop@ chenc01 dfs]$ tree.├── data└── name └── current ├── fsimage_0000000000000000000 ├── fsimage_0000000000000000000.md5 ├── seen_txid └── VERSION3 directories, 4 files
配置免密要登錄
[hadoop@ chenc01 dfs]$ ssh-keygenGenerating public/private rsa key pair.Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa.Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.The key fingerprint is:cf:4f:4e:5e:8a:4f:7e:86:e9:f6:8c:8f:77:b9:69:50 hadoop@chenc01.localdomainThe key's randomart image is: --[ RSA 2048]---- | || || || E || S . || o . || o oo .|| X * oo|| . @*= .| ----------------- [hadoop@ chenc01 dfs]$ ssh-copy-id chenc02[hadoop@ chenc01 dfs]$ ssh-copy-id chenc01 # 對自己也做一次[hadoop@ chenc01 dfs]$ ssh-copy-id chenc03
備注:方便后期復制文件或者啟動服務。因為namenode啟動時候,會鏈接到datanode上啟動對應的服務。
-
啟動hdfs
[hadoop@ chenc01 dfs]$ /home/hadoop/hadoop-3.1.3/etc/hadoop報錯:2020-03-04 16:16:45,394 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable解答:http://dl.bintray.com/sequenceiq/sequenceiq-bin/ 下載對應版本解壓,覆蓋hadoop下/lib/native/上傳之后解壓:[hadoop@ chenc01 ~]$ cd hadoop-3.1.3/lib/native/[hadoop@ chenc01 native]$ lsexamples libhadoop.so libhdfs.a libnativetask.alibhadoop.a libhadoop.so.1.0.0 libhdfs.so libnativetask.solibhadooppipes.a libhadooputils.a libhdfs.so.0.0.0 libnativetask.so.1.0.0[hadoop@ chenc01 native]$ rz[hadoop@ chenc01 native]$ tar xf hadoop-native-64.tar [hadoop@ chenc01 native]$ lsexamples libhadoop.so.1.0.0 libnativetask.ahadoop-native-64.tar libhadooputils.a libnativetask.solibhadoop.a libhdfs.a libnativetask.so.1.0.0libhadooppipes.a libhdfs.solibhadoop.so libhdfs.so.0.0.0
覆蓋完之后重啟
關閉之后在啟動
[hadoop@ chenc01 ~]$ cd /home/hadoop/hadoop-3.1.3/etc/hadoop/[hadoop@ chenc01 hadoop]$ ../../sbin/stop-dfs.sh
啟動yarn
也就是說我們要啟動 分布式計算
[hadoop@ chenc01 hadoop]$ ../../sbin/start-yarn.sh[hadoop@ chenc01 hadoop]$ ../../sbin/start-all.sh
啟動jobhistory
[hadoop@ chenc01 hadoop]$ ../../sbin/mr-jobhistory-daemon.sh start historyserver
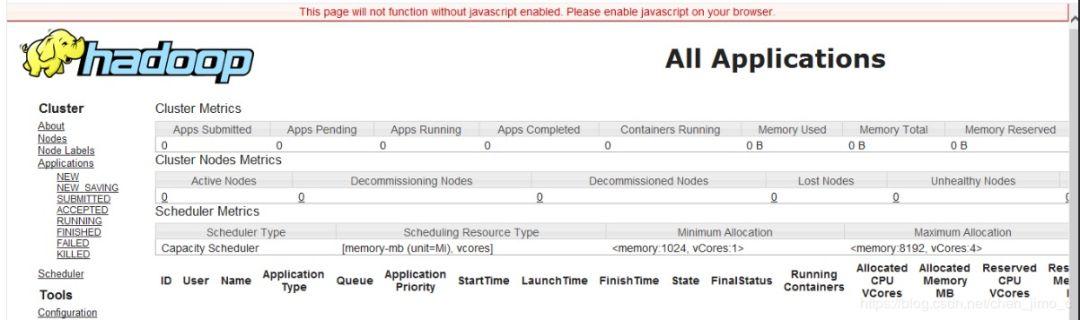
Web查看集群狀態
瀏覽器輸入http://10.0.0.61:8088/cluster